https://product.kyobobook.co.kr/detail/S000220221456
LUVIT EPL과 유튜브 데이터로 배우는 DuckDB | 이기준 - 교보문고
LUVIT EPL과 유튜브 데이터로 배우는 DuckDB | 복잡한 데이터 분석 흐름을 더 단순하게 만드는 DuckDB 최근 주목받고 있는 DuckDB를 활용해 SQL 기반 데이터 분석과 실전 프로젝트를 학습할 수 있도록 구
product.kyobobook.co.kr
TL;DR: 이 글에서는 결측값 대체(missing value imputation), 범주형 인코딩(categorical encoding), 피처 스케일링(feature scaling)과 같은 필수적인 머신러닝 데이터 전처리 작업을 SQL을 사용하여 DuckDB에서 직접 수행하는 방법을 살펴봅니다. 이러한 접근 방식은 워크플로를 단순화할 뿐만 아니라, DuckDB의 고성능 인프로세스(in-process) 실행 엔진을 활용하여 빠르고 효율적인 데이터 준비를 가능하게 합니다.
소개
데이터 전처리는 모든 머신러닝 워크플로에서 필수적인 단계이며, 모델의 성능과 유지보수 용이성 모두에 영향을 미칩니다. scikit-learn은 더 넓은 Python 생태계와의 통합 덕분에 전처리 작업에 널리 사용되지만, DuckDB는 Python 내에서 SQL 기반 데이터 변환을 수행할 수 있도록 함으로써 실용적인 대안을 제공합니다.
DuckDB의 선언형(declarative) SQL 문법은 모듈화된 워크플로를 지원하여 전처리 단계를 보다 쉽게 분리하고, 검토하며, 디버깅할 수 있게 해줍니다. 또한 DuckDB는 컬럼형 데이터 포맷에 대한 효율적인 질의를 지원하며, 전처리 로직을 SQL 스크립트로 저장할 수 있기 때문에 더욱 재현 가능하고 투명한 데이터 파이프라인을 구축할 수 있습니다.
데이터 준비
Kaggle에서 제공하는 합성 금융 거래 데이터셋을 사용합니다. 이 데이터셋은 금융 거래에서 사기 탐지에 사용되는 일반적인 정보를 포함하고 있습니다.
CREATE TABLE financial_trx AS
FROM read_csv('https://blobs.duckdb.org/data/financial_fraud_detection_dataset.csv');
먼저 SUMMARIZE를 실행하여 데이터를 분석합니다.
FROM (SUMMARIZE financial_trx)
SELECT
column_name,
column_type,
count,
null_percentage,
min;
┌─────────────────────────────┬─────────────┬─────────┬─────────────────┬────────────────────────────┐
│ column_name │ column_type │ count │ null_percentage │ min │
│ varchar │ varchar │ int64 │ decimal(9,2) │ varchar │
├─────────────────────────────┼─────────────┼─────────┼─────────────────┼────────────────────────────┤
│ transaction_id │ VARCHAR │ 5000000 │ 0.00 │ T100000 │
│ timestamp │ TIMESTAMP │ 5000000 │ 0.00 │ 2023-01-01 00:09:26.241974 │
│ sender_account │ VARCHAR │ 5000000 │ 0.00 │ ACC100000 │
│ receiver_account │ VARCHAR │ 5000000 │ 0.00 │ ACC100000 │
│ amount │ DOUBLE │ 5000000 │ 0.00 │ 0.01 │
│ transaction_type │ VARCHAR │ 5000000 │ 0.00 │ deposit │
│ merchant_category │ VARCHAR │ 5000000 │ 0.00 │ entertainment │
│ location │ VARCHAR │ 5000000 │ 0.00 │ Berlin │
│ device_used │ VARCHAR │ 5000000 │ 0.00 │ atm │
│ is_fraud │ BOOLEAN │ 5000000 │ 0.00 │ false │
│ fraud_type │ VARCHAR │ 5000000 │ 96.41 │ card_not_present │
│ time_since_last_transaction │ DOUBLE │ 5000000 │ 17.93 │ -8777.814181944444 │
│ spending_deviation_score │ DOUBLE │ 5000000 │ 0.00 │ -5.26 │
│ velocity_score │ BIGINT │ 5000000 │ 0.00 │ 1 │
│ geo_anomaly_score │ DOUBLE │ 5000000 │ 0.00 │ 0.0 │
│ payment_channel │ VARCHAR │ 5000000 │ 0.00 │ ACH │
│ ip_address │ VARCHAR │ 5000000 │ 0.00 │ 0.0.102.150 │
│ device_hash │ VARCHAR │ 5000000 │ 0.00 │ D1000002 │
├─────────────────────────────┴─────────────┴─────────┴─────────────────┴────────────────────────────┤
│ 18 rows 5 columns │
└────────────────────────────────────────────────────────────────────────────
피처 인코딩
위의 데이터 통계 정보를 보면 transaction_type, merchant_category, payment_channel과 같은 범주형 컬럼이 몇 개 존재합니다. 대부분의 머신러닝 모델은 수치형 입력을 요구하기 때문에 이러한 데이터는 숫자 형태로 변환됩니다. 이 과정을 인코딩(encoding)이라고 하며, 여러 가지 방법으로 수행할 수 있습니다. 아래에서는 SQL을 사용하여 몇 가지 대표적인 인코딩 기법을 살펴봅니다.
이 글에서는 DuckDB의 여러 “친화적인 SQL(Friendly SQL)” 기능을 사용합니다. 여기에는 FROM-first 문법과 접두사 별칭(prefix aliases)이 포함됩니다.
원-핫 인코딩 (One-Hot Encoding)
범주형 컬럼에 원-핫 인코딩을 적용하면 각 고유 값이 별도의 컬럼으로 변환되며, 해당 값과 일치하면 1, 그렇지 않으면 0이 부여됩니다.
FROM financial_trx
SELECT DISTINCT
transaction_type,
deposit_onehot: (transaction_type = 'deposit')::INT,
payment_onehot: (transaction_type = 'payment')::INT,
transfer_onehot: (transaction_type = 'transfer')::INT,
withdrawal_onehot: (transaction_type = 'withdrawal')::INT
ORDER BY transaction_type;
┌──────────────────┬────────────────┬────────────────┬─────────────────┬───────────────────┐
│ transaction_type │ deposit_onehot │ payment_onehot │ transfer_onehot │ withdrawal_onehot │
│ varchar │ int32 │ int32 │ int32 │ int32 │
├──────────────────┼────────────────┼────────────────┼─────────────────┼───────────────────┤
│ deposit │ 1 │ 0 │ 0 │ 0 │
│ payment │ 0 │ 1 │ 0 │ 0 │
│ transfer │ 0 │ 0 │ 1 │ 0 │
│ withdrawal │ 0 │ 0 │ 0 │ 1 │
└──────────────────┴────────────────┴────────────────┴─────────────────┴───────────────────┘
원-핫 인코딩을 수행하는 또 다른 방법은 PIVOT 문을 사용하는 것입니다.
PIVOT financial_trx
ON transaction_type
USING coalesce(max(transaction_type = transaction_type)::INT, 0) AS onehot
GROUP BY transaction_type;
위 구문에서는 다음을 수행합니다.
- transaction_type 범주형 컬럼을 기준으로 피벗합니다.
- 피벗 조건은 transaction_type이 자기 자신의 각 값과 일치하는지 여부입니다.
- 불리언 값을 정수로 변환한 뒤 max 집계를 적용합니다.
- 변환된 컬럼 이름은 transaction_type 값 뒤에 _onehot 접미사가 붙도록 지정합니다.
원-핫 인코딩해야 할 범주형 컬럼이 여러 개라면 PIVOT을 서브쿼리나 WITH 절에서 사용할 수 있습니다.
WITH onehot_trx_type AS (
PIVOT financial_trx
ON transaction_type
USING coalesce(max(transaction_type = transaction_type)::INT, 0) AS onehot
GROUP BY transaction_type
), onehot_payment_channel AS (
PIVOT financial_trx
ON payment_channel
USING coalesce(max(payment_channel = payment_channel)::INT, 0) AS onehot
GROUP BY payment_channel
)
SELECT
financial_trx.*,
onehot_trx_type.* LIKE '%\_onehot' ESCAPE '\',
onehot_payment_channel.* LIKE '%\_onehot' ESCAPE '\'
FROM financial_trx
INNER JOIN onehot_trx_type USING (transaction_type)
INNER JOIN onehot_payment_channel USING (payment_channel);
위 쿼리에서는 컬럼명에 대해 LIKE 연산자를 사용하여 _onehot으로 끝나는 모든 컬럼을 가져옵니다.
순서형 인코딩 (Ordinal Encoding)
순서형 인코딩은 각 범주형 값에 고유한 식별자를 부여하는 방식이며, 일반적으로 범주 간에 계층적 순서가 존재할 때 사용됩니다. 예를 들어, 거래 유형을 기준으로 정렬한 후 row_number 함수를 사용하여 식별자를 부여할 수 있습니다.
WITH trx_type_ordinal_encoded AS (
SELECT
transaction_type,
trx_type_oe: row_number() OVER (ORDER BY transaction_type) - 1
FROM (
SELECT DISTINCT transaction_type
FROM financial_trx
)
)
SELECT
transaction_type,
trx_type_oe,
number_trx: count(*)
FROM financial_trx
INNER JOIN trx_type_ordinal_encoded USING (transaction_type)
GROUP BY ALL
ORDER BY trx_type_oe;
┌──────────────────┬─────────────┬────────────┐
│ transaction_type │ trx_type_oe │ number_trx │
│ varchar │ int64 │ int64 │
├──────────────────┼─────────────┼────────────┤
│ deposit │ 0 │ 1250593 │
│ payment │ 1 │ 1250438 │
│ transfer │ 2 │ 1250334 │
│ withdrawal │ 3 │ 1248635 │
└──────────────────┴─────────────┴────────────┘
레이블 인코딩 (Label Encoding)
레이블 인코딩은 순서형 인코딩과 마찬가지로 고유한 식별자를 부여하지만, 값의 순서를 고려하지 않습니다. 일반적으로 출력 데이터에 적용됩니다.
WITH trx_type_label_encoded AS (
SELECT
transaction_type,
trx_type_le: row_number() OVER () - 1
FROM (
SELECT DISTINCT transaction_type
FROM financial_trx
)
)
SELECT
transaction_type,
trx_type_le,
number_trx: count(*)
FROM financial_trx
INNER JOIN trx_type_label_encoded USING (transaction_type)
GROUP BY ALL
ORDER BY trx_type_le;
┌──────────────────┬─────────────┬────────────┐
│ transaction_type │ trx_type_le │ number_trx │
│ varchar │ int64 │ int64 │
├──────────────────┼─────────────┼────────────┤
│ deposit │ 0 │ 1250593 │
│ withdrawal │ 1 │ 1248635 │
│ payment │ 2 │ 1250438 │
│ transfer │ 3 │ 1250334 │
└──────────────────┴─────────────┴────────────┘
동일한 결과는 array_agg와 같은 리스트 함수로 고유값 배열을 생성한 뒤, list_position을 사용하여 각 값의 위치를 추출하는 방식으로도 구현할 수 있습니다.
WITH trx_ref AS (
SELECT trx_type_values: array_agg(DISTINCT transaction_type)
FROM financial_trx
)
SELECT
transaction_type,
trx_type_le: list_position(trx_type_values, transaction_type) - 1,
number_trx: count(*)
FROM
financial_trx,
trx_ref
GROUP BY ALL
ORDER BY trx_type_le;
┌──────────────────┬─────────────┬────────────┐
│ transaction_type │ trx_type_le │ number_trx │
│ varchar │ int32 │ int64 │
├──────────────────┼─────────────┼────────────┤
│ payment │ 0 │ 1250438 │
│ deposit │ 1 │ 1250593 │
│ transfer │ 2 │ 1250334 │
│ withdrawal │ 3 │ 1248635 │
└──────────────────┴─────────────┴────────────┘
위 쿼리들은 비결정적(non-deterministic)이므로, 증분 처리(incremental processing)를 수행하는 경우에는 정렬을 적용하거나 참조 테이블(reference table)에 값을 저장하는 것이 필요할 수 있습니다.
피처 스케일링
머신러닝에서 또 다른 일반적인 데이터 전처리 단계는 수치형 피처의 스케일을 조정하는 것입니다. 이는 서로 다른 피처들의 값 범위나 분포를 유사한 수준으로 맞추기 위한 작업입니다. 스케일링(scaling)은 피처 정규화(feature normalization) 또는 표준화(standardization)라고도 하며, 일반적으로 피처를 일정한 범위(예: 0~1)로 재조정하거나 평균이 0이고 표준편차가 1이 되도록 변환합니다. 이러한 과정이 필요한 이유는 많은 알고리즘이 거리 계산이나 경사 하강법 기반의 업데이트를 수행하는데, 피처 간 스케일 차이가 크면 결과가 왜곡될 수 있기 때문입니다.
인코딩은 전체 범주 목록을 알아야 하므로 일반적으로 원본 데이터 전체를 대상으로 수행되지만, 스케일링은 데이터 누수(data leakage)를 방지하기 위해 학습 데이터와 테스트 데이터로 분리한 후 수행해야 합니다. DuckDB에서는 샘플링을 사용하여 데이터를 분할할 수 있습니다.
SET threads = 1;
CREATE TABLE financial_trx_training AS
FROM financial_trx
USING SAMPLE 80 PERCENT (reservoir, 256);
SET threads = 8;
CREATE TABLE financial_trx_testing AS
FROM financial_trx
ANTI JOIN financial_trx_training USING (transaction_id);
샘플링 시 DuckDB를 단일 스레드로 설정하고 시드를 지정하여 재현 가능한 샘플을 생성합니다. 또한 reservoir 샘플링 전략을 사용하여 정확히 80%의 레코드가 샘플에 포함되도록 합니다.
표준 스케일링 (Standard Scaling)
표준 스케일링은 각 수치형 피처에서 평균을 빼고 표준편차로 나누어 평균이 0, 표준편차가 1이 되도록 변환하는 전처리 기법입니다.
예를 들어 velocity_score에 대해 표준 스케일링을 수행하려면 다음과 같이 실행할 수 있습니다.
WITH scaling_params AS (
SELECT
avg_velocity_score: avg(velocity_score),
stddev_pop_velocity_score: stddev_pop(velocity_score)
FROM financial_trx_training
)
SELECT
ss_velocity_score: (velocity_score - avg_velocity_score) /
stddev_pop_velocity_score
FROM
financial_trx_testing,
scaling_params;
위 쿼리는 DuckDB 매크로를 사용하여 훨씬 간단하게 만들 수 있습니다. 스칼라 매크로를 사용하면 표준 스케일러 변환 함수를 정의할 수 있습니다.
CREATE OR REPLACE MACRO standard_scaler(val, avg_val, std_val) AS
(val - avg_val) / std_val;
테이블 매크로를 사용하면 표준 스케일러에 필요한 스케일링 파라미터를 반환하는 함수를 만들 수 있습니다.
CREATE OR REPLACE MACRO scaling_params(table_name, column_list) AS TABLE
FROM query_table(table_name)
SELECT
"avg_\0": avg(columns(column_list)),
"std_\0": stddev_pop(columns(column_list));
위 매크로 정의에서는 다음을 수행합니다.
- query_table을 사용하여 어떤 테이블이든 입력으로 받아 조회할 수 있습니다.
- 컬럼 표현식(column expressions)을 사용하여 입력된 컬럼 목록 전체에 집계 함수를 적용합니다.
- 별칭 정의에서 \0을 사용하여 원래 컬럼명을 기반으로 집계 컬럼 이름을 생성합니다.
이제 다음과 같이 표준 스케일링을 계산할 수 있습니다.
SELECT
ss_velocity_score: standard_scaler(
velocity_score,
avg_velocity_score,
std_velocity_score
),
ss_spending_deviation_score: standard_scaler(
spending_deviation_score,
avg_spending_deviation_score,
std_spending_deviation_score
)
FROM financial_trx_testing,
scaling_params(
'financial_trx_training',
['velocity_score', 'spending_deviation_score']
);
최소-최대 스케일링 (Min-Max Scaling)
최소-최대 스케일링은 피처 값을 고정된 범위(일반적으로 0~1)로 변환하는 정규화 기법입니다. 최소값을 뺀 뒤 범위(max - min)로 나누어 계산합니다. 이 방법은 원래 분포의 형태를 유지하면서 모든 값을 동일한 스케일로 맞춰줍니다.
이를 위해 먼저 scaling_params 매크로를 확장하여 입력 컬럼 목록에 대한 최소값과 최대값을 계산하도록 합니다.
CREATE OR REPLACE MACRO scaling_params(table_name, column_list) AS TABLE
FROM query_table(table_name)
SELECT
"avg_\0": avg(columns(column_list)),
"std_\0": stddev_pop(columns(column_list)),
"min_\0": min(columns(column_list)),
"max_\0": max(columns(column_list));
다음으로 최소-최대 스케일링 계산을 위한 매크로를 정의합니다.
CREATE OR REPLACE MACRO min_max_scaler(val, min_val, max_val) AS
(val - min_val) / nullif(max_val - min_val, 0);
마지막으로 값을 계산합니다.
SELECT
min_max_velocity_score: min_max_scaler(
velocity_score,
min_velocity_score,
max_velocity_score
),
min_max_spending_deviation_score: min_max_scaler(
spending_deviation_score,
min_spending_deviation_score,
max_spending_deviation_score
)
FROM financial_trx_testing,
scaling_params(
'financial_trx_training',
['velocity_score', 'spending_deviation_score']
);
강건 스케일링 (Robust Scaling)
강건 스케일링은 수치형 피처에서 중앙값(median)을 빼고 사분위 범위(IQR, Interquartile Range)로 나누어 변환하는 정규화 기법입니다. 평균과 표준편차를 사용하는 표준 스케일링과 달리 데이터의 가운데 50% 구간에 집중하기 때문에 이상치의 영향을 줄일 수 있습니다. 따라서 왜도가 크거나 극단값이 포함된 데이터셋에 적합합니다.
DuckDB에서는 quantile_cont 통계 집계 함수를 사용하여 분위수를 계산할 수 있습니다.
CREATE OR REPLACE MACRO scaling_params(table_name, column_list) AS TABLE
FROM query_table(table_name)
SELECT
"avg_\0": avg(columns(column_list)),
"std_\0": stddev_pop(columns(column_list)),
"min_\0": min(columns(column_list)),
"max_\0": max(columns(column_list)),
"q25_\0": quantile_cont(columns(column_list), 0.25),
"q50_\0": quantile_cont(columns(column_list), 0.50),
"q75_\0": quantile_cont(columns(column_list), 0.75);
강건 스케일링 계산을 위한 스칼라 매크로를 정의합니다.
CREATE OR REPLACE MACRO robust_scaler(val, q25_val, q50_val, q75_val) AS
(val - q50_val) / nullif(q75_val - q25_val, 0);
그리고 다른 스케일링 변환과 마찬가지로 SQL에서 직접 호출할 수 있습니다.
SELECT
rs_velocity_score: robust_scaler(
velocity_score,
q25_velocity_score,
q50_velocity_score,
q75_velocity_score
),
rs_spending_deviation_score: robust_scaler(
spending_deviation_score,
q25_spending_deviation_score,
q50_spending_deviation_score,
q75_spending_deviation_score
)
FROM financial_trx_testing,
scaling_params(
'financial_trx_training',
['velocity_score', 'spending_deviation_score']
);
결측값 처리
입력 데이터가 불완전한 경우, 즉 결측 데이터가 포함된 경우가 자주 발생합니다. 사용 사례에 따라 이러한 데이터는 제외되거나, 그대로 사용되거나, 상수 값으로 채워집니다. DuckDB에서는 컬럼이 NULL인 경우 해당 컬럼의 값 또는 기본값을 가져오기 위해 coalesce 함수를 사용할 수 있습니다.
일반적인 기법은 다음과 같습니다.
- 결측값을 상수로 대체합니다.
- 결측값을 평균으로 대체합니다.
- 결측값을 중앙값으로 대체합니다.
중앙값 계산을 추가하여 scaling_params 매크로를 확장합니다.
CREATE OR REPLACE MACRO scaling_params(table_name, column_list) AS TABLE
FROM query_table(table_name)
SELECT
"avg_\0": avg(columns(column_list)),
"std_\0": stddev_pop(columns(column_list)),
"min_\0": min(columns(column_list)),
"max_\0": max(columns(column_list)),
"q25_\0": quantile_cont(columns(column_list), 0.25),
"q50_\0": quantile_cont(columns(column_list), 0.50),
"q75_\0": quantile_cont(columns(column_list), 0.75),
"median_\0": median(columns(column_list));
그리고 사용 사례에 따라 결측값을 처리하기 위해 coalesce를 적용합니다.
SELECT
time_since_last_transaction_with_0: coalesce(time_since_last_transaction, 0),
time_since_last_transaction_with_mean: coalesce(time_since_last_transaction, avg_time_since_last_transaction),
time_since_last_transaction_with_libraryn: coalesce(time_since_last_transaction, median_time_since_last_transaction)
FROM
financial_trx_testing,
scaling_params('financial_trx_training', ['time_since_last_transaction'])
WHERE time_since_last_transaction IS NULL;
결측 데이터 채우기는 피처 스케일링 전에 수행해야 합니다.
벤치마크
위의 데이터 처리 단계들을 하나로 모아, scikit-learn 데이터 전처리 파이프라인과 실행 시간을 비교하는 벤치마크를 수행하기로 했습니다. 코드는 블로그 예제 저장소에서 확인할 수 있습니다.
scikit-learn에서는 데이터 전처리가 변환기(transformer)와 파이프라인(pipeline)을 통해 수행됩니다. 변환기는 fit과 transform 메서드를 구현하는 클래스이며, 파이프라인은 특정 순서로 데이터에 적용되는 변환기들의 시퀀스입니다. 별도로 지정하지 않는 한, 파이프라인의 각 단계는 변환 단계의 결과만을 numpy 배열로 반환합니다. 반면 DuckDB에서는 SQL 표현식을 통해 데이터를 변환하므로, 각 단계 이후 전체 데이터셋을 확인할 수 있습니다. 따라서 이번 벤치마크에서 scikit-learn 데이터 전처리 단계에는 다음 변환이 포함됩니다.
- 변환 단계의 출력은 pandas로 설정합니다.
- remainder='passthrough'를 설정하여 모든 컬럼이 변환 단계를 통과하도록 합니다.
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
def scikit_feature_scaling_training_data(x_train):
impute_missing_data = Pipeline(
[
("imputer", SimpleImputer(strategy="mean")),
("scaler", MinMaxScaler(copy=False)),
]
)
scaling_steps = ColumnTransformer(
[
(
"ss",
StandardScaler(copy=False),
["velocity_score"]
),
(
"minmax_time_since_last_transaction",
impute_missing_data,
["time_since_last_transaction"],
),
(
"minmax",
MinMaxScaler(copy=False),
["spending_deviation_score"]
),
(
"rs",
RobustScaler(copy=False),
["amount"]
),
],
remainder="passthrough",
verbose_feature_names_out=False,
)
scaling_steps.set_output(transform="pandas")
scaling_steps.fit(x_train)
return scaling_steps, scaling_steps.transform(x_train)
아래 그림은 16GB 메모리를 갖춘 MacBook Pro에서의 실행 시간을 보여주며, DuckDB가 데이터 전처리 단계에서 scikit-learn보다 상당한 성능 향상을 제공한다는 점을 보여줍니다.
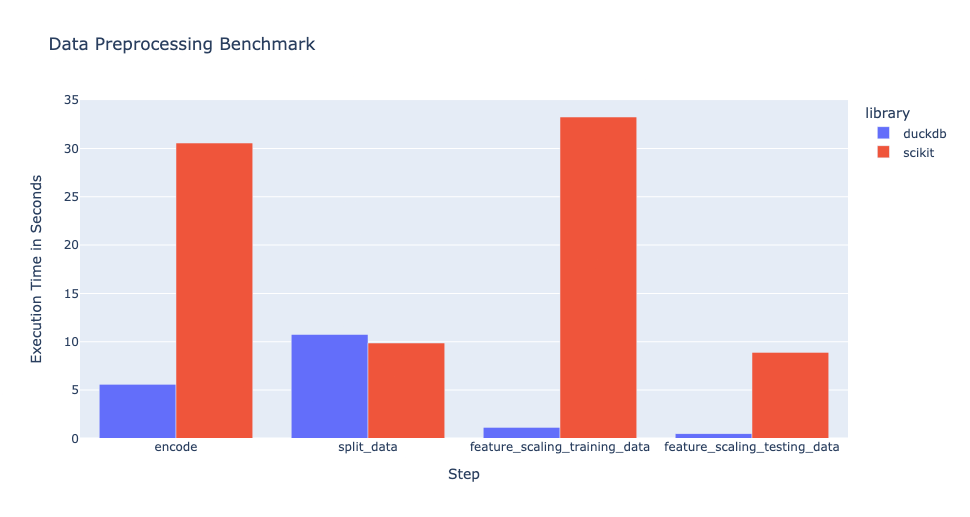
이 스크립트에서는 DuckDB와 scikit-learn 전처리 단계의 결과를 대조하여, 두 구현이 동일한 결과를 생성한다는 점을 보여줍니다.
위의 예제에서는 학습 과정에서 SQL 표현식을 사용하여 데이터 전처리를 수행하는 방법을 살펴보았습니다. 실제 환경에서는 새로운 데이터가 학습 데이터와 동일한 방식으로 변환될 수 있도록, 추론(inference) 시점에도 동일한 전처리 단계를 적용해야 합니다.
scikit-learn에서는 파이프라인을 모델과 함께 저장한 뒤, 추론 시 해당 파이프라인을 적용함으로써 이를 수행합니다. DuckDB에서는 원본 학습 데이터(또는 학습 과정에서 계산된 scaling_params 매크로의 결과값)를 저장함으로써 동일한 일관성을 확보할 수 있습니다.
비록 (변환된) 학습 데이터의 크기가 모델 아티팩트보다 훨씬 크더라도, 학습 시점의 데이터와 계산된 피처를 버전 관리하는 것은 일반적인 관행입니다. 이러한 방식은 모델의 추적 가능성(traceability)과 재현 가능성(reproducibility)을 보장합니다.
효율적인 (학습) 데이터 관리를 위해서는 DuckLake와 같이 시점 복원(Time Travel) 기능을 제공하는 솔루션을 활용할 수 있습니다.
결론
이 글에서는 DuckDB가 머신러닝 워크플로를 위한 데이터 전처리에 대해 성능이 뛰어나고 SQL 중심적인 접근 방식을 제공한다는 점을 살펴보았습니다. 결측값 대체, 범주형 인코딩, 피처 스케일링과 같은 작업을 데이터베이스 엔진 내부에서 직접 처리함으로써, 학습 과정에서 불필요한 데이터 이동을 제거하고 전처리 지연 시간을 줄일 수 있습니다.
'EPL과 유튜브 데이터로 배우는 DuckDB' 카테고리의 다른 글
| AI 시대의 DuckDB 확장 전략 (0) | 2026.06.13 |
|---|---|
| Arrow, Pandas, DuckDB로 다루는 연합 데이터 (0) | 2026.06.08 |
| DuckDB의 더 친숙한 SQL - Part 4 (0) | 2026.06.07 |
| DuckDB와 AI로 대용량 데이터셋 분석하기: 초보자 가이드 (0) | 2026.06.07 |
| DuckDB: 2026년 데이터 분석가들이 가장 과소평가하는 도구 (0) | 2026.06.07 |




댓글