MVP(Minimum Viable Product) 버전의 Causal Inference Application은 원래 데이터 사이언스 면접을 위해 개발되었지만, 예상치 못하게 업계 기술 전문가들 사이에서 어느 정도 관심을 받게 되었습니다. 이러한 반응은 인과 AI(Causal AI)가 현재 업계에서 주목받는 주제임을 보여주었습니다. 저는 경제학 배경을 가지고 있어 인과추론 개념에는 익숙했지만, 금융 리스크 관리 분야에서 5년 동안 일하는 동안 이러한 방법론을 실제로 적용할 기회는 없었습니다. 또한 2020년에 기술 업계로 이동한 이후에도 업무 대부분은 비교적 단순한 A/B 테스트에 집중되어 있었고, 관찰 데이터에 대한 인과추론은 가끔 활용하는 수준에 그쳤습니다.
이러한 배경에서 저는 관련 지식을 다시 정리해 보기로 했고, 먼저 문헌 조사부터 시작했습니다. AI의 도움 덕분에 AI 챗봇을 활용하여 이 주제에 대한 심층 연구를 손쉽게 시작할 수 있었습니다. 초기 애플리케이션을 개발하면서, 제가 10여 년 전에 배웠던 전통적인 인과추론 방법론에서 현대적인 인과 머신러닝 알고리즘으로의 전환을 확인할 수 있었습니다. 이에 따라 초기 버전에는 Double Machine Learning(DML)과 Meta-Learners(S-Learner, T-Learner) 같은 최신 기법도 일부 포함했습니다.
제 생각에 이러한 복잡한 방법들은 핵심 비즈니스 문제를 해결한다는 측면에서는 선형회귀(Linear Regression)나 성향점수매칭(Propensity Score Matching)과 같은 전통적인 방법과 본질적으로 크게 다르지 않습니다. 다만 교란변수(X)와 결과변수(y) 사이의 더 복잡한 관계를 포착할 수 있다는 점에서 향상된 성능을 제공합니다.
하지만 이러한 초기 방법들의 중요한 한계는 “처리 집단(treated)”과 “비처리 집단(non-treated)” 간의 횡단면 비교에 초점을 맞춘다는 점입니다. 따라서 시간에 따른 인과효과를 추정하는 데에는 한계가 있습니다. Difference-in-Differences(DiD) 역시 시간 요소를 포함하고 있지만, 일반적으로 고정된 기간 내에서의 비교에 초점을 둘 뿐 동적이고 연속적인 시계열상의 인과효과를 추정하는 것은 아닙니다.
이러한 공백을 메우기 위해 저는 Bayesian Structural Time Series(BSTS)를 애플리케이션에 추가하게 되었습니다. BSTS는 Google의 연구(Scott and Varian, 2014; Brodersen et al., 2015)를 통해 널리 알려졌으며, 현재 시계열 데이터에서 인과효과를 추정하는 업계 표준 방법 중 하나로 자리 잡고 있습니다.
베이지안 구조적 시계열(BSTS)
베이지안 구조적 시계열(Bayesian Structural Time Series, BSTS) 모델은 시계열 데이터에 대한 인과추론을 수행하기 위한 강력한 통계 기법입니다. 특히 무작위 통제집단(randomized control group)을 확보할 수 없는 상황에서 제품 출시, 마케팅 캠페인, 정책 변경과 같은 개입(intervention)의 효과를 평가하는 데 매우 유용합니다.
BSTS는 시계열을 추세(trend), 계절성(seasonality), 그리고 공변량(covariates)의 회귀 효과(regression effects)와 같은 여러 관측되지 않는 구성요소들의 결합으로 모델링합니다. BSTS의 인과추론 능력의 핵심은 합성 반사실(synthetic counterfactual)을 생성하는 능력에 있습니다. 즉, 개입이 발생하지 않았더라면 결과 지표가 어떻게 되었을지를 예측하는 것입니다. BSTS 모델의 일반적인 형태는 다음과 같이 표현됩니다(Scott and Varian, 2014).

베이지안 모델인 BSTS는 인과효과에 대한 전체 사후분포(posterior distribution)를 제공합니다. 이는 단순한 점 추정치(point estimate)보다 더 견고하고 완전한 추정 결과를 제공합니다.
모델은 개입 이전(pre-intervention) 데이터를 사용하여 학습되며, 이를 기반으로 반사실(counterfactual), 즉 처치가 없었을 경우의 관측되지 않은 결과를 예측합니다. 이후 인과효과는 개입 이후(post-intervention)에 실제로 관측된 데이터와 모델이 예측한 반사실 간의 차이로 계산됩니다.
Python 구현
BSTS는 원래 Brodersen et al.(2015)에 의해 R로 구현되었습니다. 제 애플리케이션은 Python으로 작성되었기 때문에, 이에 상응하는 Python 라이브러리를 찾아보았습니다. 사용 가능한 패키지 세 가지를 찾았고, Gemini에게 이들에 대한 비교표를 생성해 달라고 요청했습니다.
| 로직/백엔드 | statsmodels (우도 기반) | TensorFlow Probability (상태공간 모델) | PyMC (확률 프로그래밍) |
| 통계 엔진 | 빈도주의(Frequentist) 근사 방식. MLE(최대우도추정)를 사용하여 칼만 필터를 적합함. | 완전한 베이지안 방식(Fully Bayesian). MCMC(Gibbs/HMC) 또는 변분추론(Variational Inference)을 사용함. | 완전한 베이지안 방식(Fully Bayesian). NUTS(고급 HMC)와 ArviZ를 사용함. |
| 개발자 / 관리 주체 | Jamal Senouci (Dafiti의 Willian Fuks가 구현한 로직 기반) | Google (Colin Carroll, David Moore, Jacob Burnim, Kyle Loveless, Susanna Makela) | PyMC Labs (Ben Vincent, Luciano Paz 외) |
| 주요 강점 | 속도와 단순성. 학습 곡선이 거의 없으며 즉시 설치 가능하고 몇 초 안에 실행됨. | 엄밀성과 확장성. 대규모 데이터에 대해 GPU 가속을 지원하며 Google 연구와 자연스럽게 연계됨. | 유연성. 사용자 정의 인과 그래프, 계층적 모델, 사용자 정의 사전분포(prior)를 구축할 수 있음. |
| 주요 약점 | 유지보수 및 안정성. 레거시 코드 기반이며 p-value가 취약하여 노이즈를 과소평가하는 경우가 많음. | 복잡성. TensorFlow 등 무거운 의존성이 필요하며 CPU 환경에서는 실행 속도가 느릴 수 있음. | 수동 설정 필요. 명시적인 수식 작성이 필요하며 베이지안 방법에 익숙하지 않은 사용자에게는 학습 곡선이 가파름. |
| 권장 사용 사례 | 애드혹 탐색적 분석. 일반적인 웹 지표에 대한 빠른 내부 보고서 작성. | 프로덕션 파이프라인. 수천 개 세그먼트에 대한 자동화된 고중요도 보고. | 학술 연구 / HTE(Heterogeneous Treatment Effect). 복잡한 사용자 간 상호작용(spillover)이나 세그먼트 효과를 모델링해야 하는 경우. |
이 표는 주요 차이가 샘플링 방법에 있음을 보여줍니다. tfp-causalimpact는 Scott and Varian(2014)의 방법론을 정확히 구현한 것이며, 원래 Brodersen et al.(2015)의 R 패키지인 CausalImpact와 동일합니다. 반면 Python 패키지인 CausalImpact는 최대우도추정(Maximum Likelihood Estimation, MLE)을 사용합니다. 이는 진정한 베이지안 추정량이 아니며, 과적합에 더 취약합니다.
하지만 CausalImpact 구현은 사용하기 더 쉽고 실행 시간이 훨씬 빠르기 때문에, 저는 애플리케이션 성능을 최적화하기 위해 이 패키지를 선택했습니다.
V3 앱 데모
이제 앱 내에서 BSTS를 사용하여 마케팅 캠페인이 일일 매출에 미친 인과효과를 추정하는 예제를 살펴보겠습니다.
Step 1: 데이터 불러오기
첫 번째 단계는 시뮬레이션된 시계열 데이터셋을 불러오는 것입니다. 이 데이터셋에는 지역(region), 일일 매출(daily revenue), 마케팅 지출(marketing spend), 그리고 개입 기간(intervention period) 및 개입 지역을 나타내는 변수들이 포함되어 있습니다.
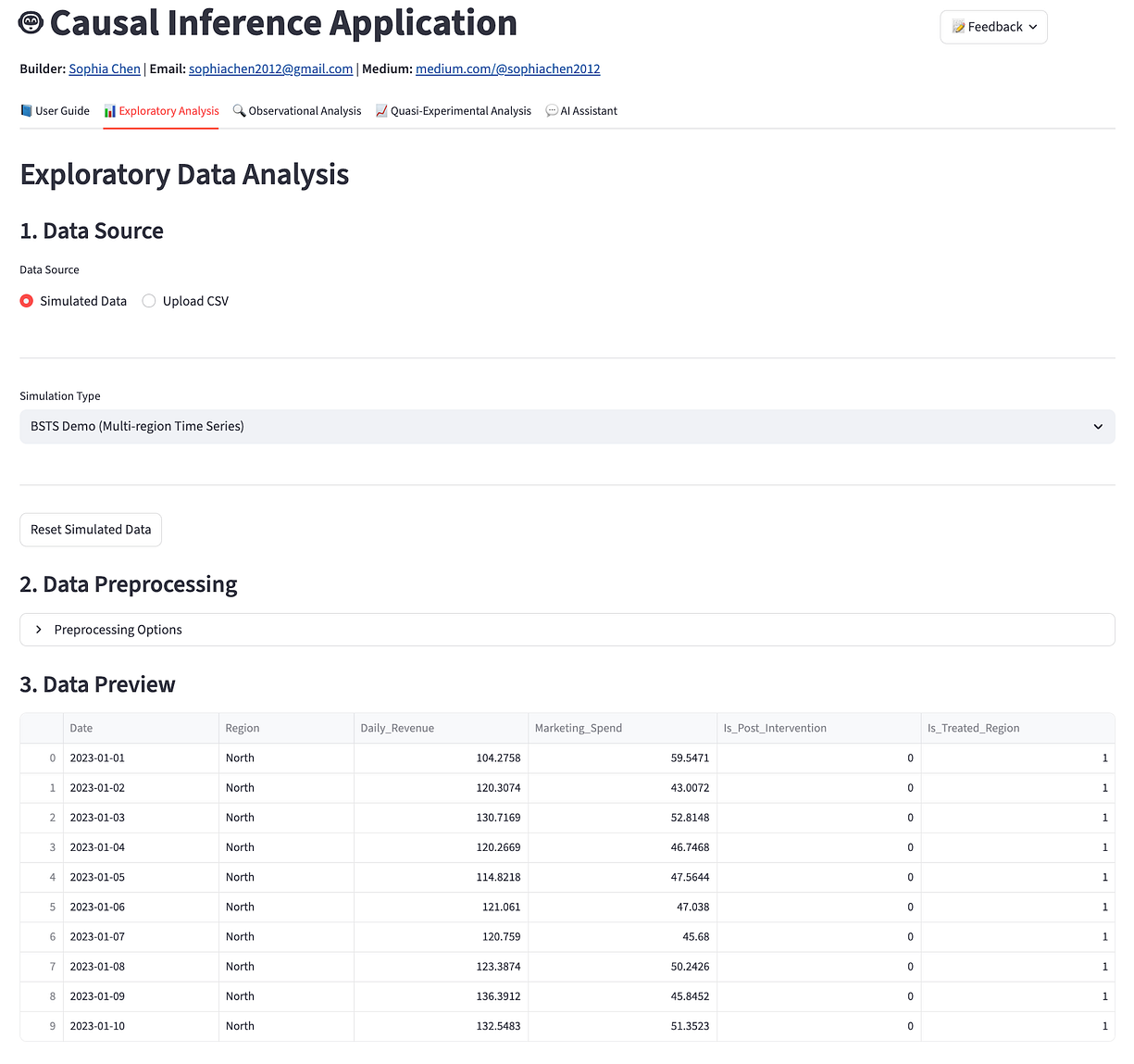
Step 2: 탐색적 분석
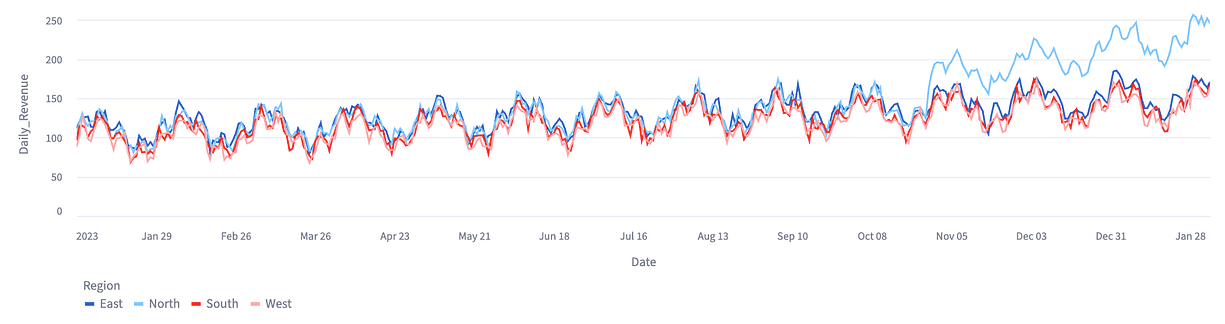
앱은 각 변수에 대한 기초 통계를 요약하여 제공하며, 탐색적 분석(Exploratory Analysis) 탭에서는 차트 빌더를 사용하여 계절성(seasonality)과 추세(trend)를 시각화할 수 있습니다.
이 예제에서는 개입이 2023년 10월 28일경에 시작되었음을 확인할 수 있으며, 북부 지역(North region)은 해당 시점 이후 일일 매출이 눈에 띄게 증가한 모습을 보입니다.
만약 명확한 이상치(outlier)나 결측치(missing data)가 존재한다면, BSTS 추정을 수행하는 준실험 분석(Quasi-experimental Analysis) 탭으로 이동하기 전에 데이터 전처리를 수행해야 합니다.


Step 3: BSTS 추정 실행
다음 단계는 BSTS 모델을 설정하고 실행하는 것입니다. 결과 변수(outcome column)와 개입 날짜(intervention date)를 지정하는 것 외에도, 거시경제 지표와 같은 추가적인 통제 변수(control variables)를 포함할 수 있습니다.
또한 반사실(counterfactual)을 생성하기 위해 합성 통제집단(synthetic control group)을 구성할지 여부를 선택할 수도 있습니다.

1. 합성 통제집단(Synthetic Control) 없이
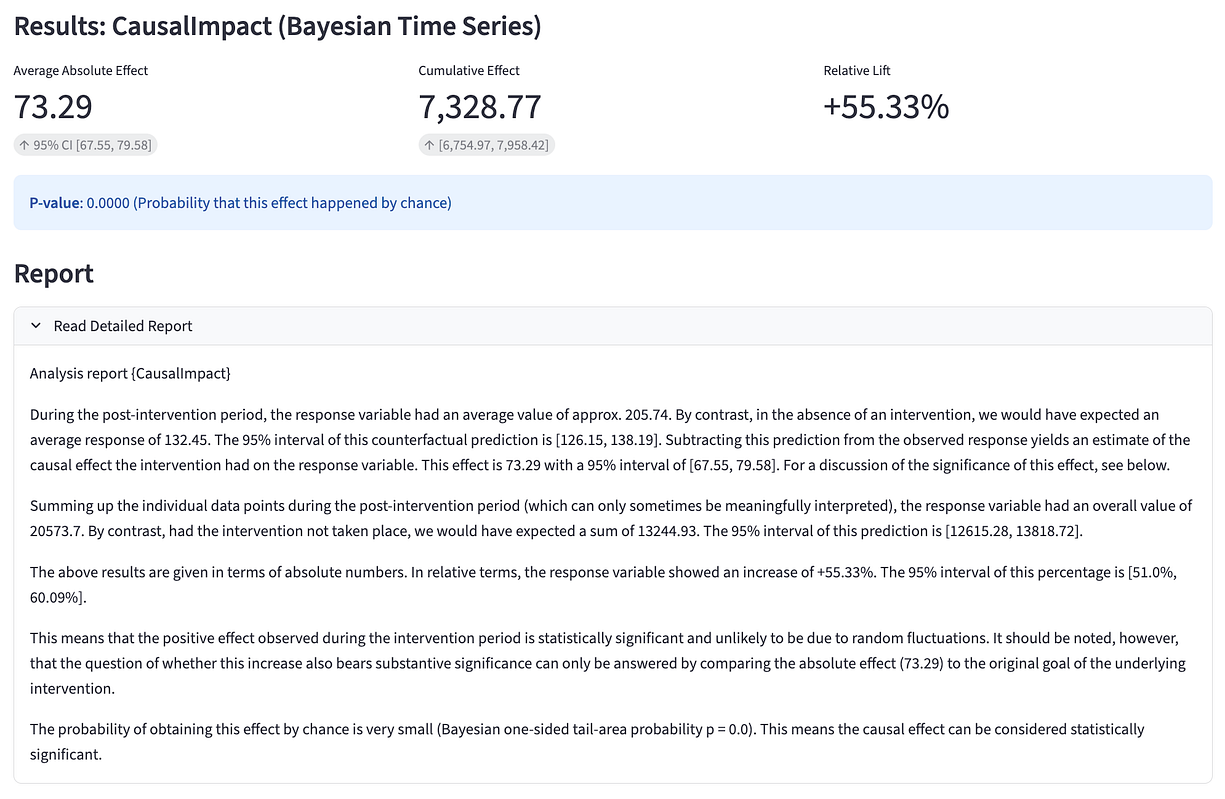
먼저 기준 시나리오부터 시작합니다. 처치(treatment)가 North 지역에만 적용되었으므로, North 지역의 일일 매출 시계열만 사용하여 인과효과를 추정합니다. CausalImpact 패키지는 결과 요약(summary)과 상세 보고서(report)를 모두 제공합니다.
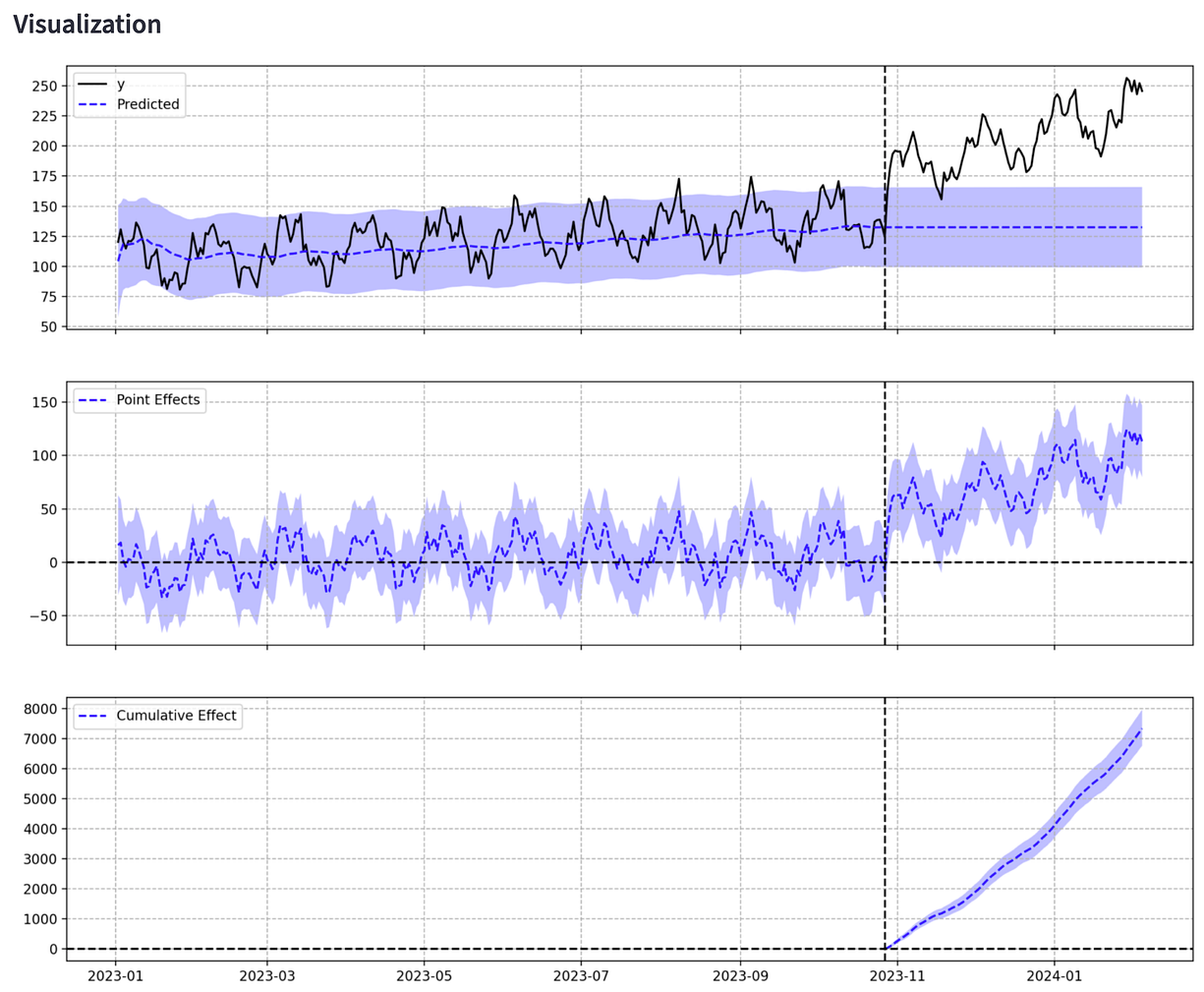
합성 통제집단을 사용하지 않은 경우, 개입 이후 일일 매출이 55.3% 증가한 것으로 추정되었습니다. 앱은 점 추정치(point estimate)와 누적 추정치(cumulative estimate), 그리고 각각의 신뢰구간(confidence interval)을 시각화하여 제공합니다.
2. 합성 통제집단(Synthetic Control) 사용
인과추론의 핵심 요소 중 하나는 "개입이 없었다면 어떻게 되었을까?"라는 질문에 답하기 위한 신뢰할 수 있는 반사실(counterfactual)을 구축하는 것입니다. 인과모형은 이러한 반사실 시나리오를 생성하고 실제 관측값과 비교합니다. 실제 관측값은 고정되어 있지만, 편향되지 않은 반사실을 구축하는 것은 쉽지 않은 문제입니다.
앞서 살펴본 기준 시나리오는 North 지역의 과거 일일 매출 데이터만을 활용하며, 모든 잠재적 정보가 이미 해당 시계열에 반영되어 있다고 가정합니다. 그러나 처치 기간 동안 개입과 무관한 정책 변화나 거시경제 변화가 발생할 수 있습니다. 이 경우 처치 대상의 과거 데이터만을 이용하여 생성한 반사실은 편향될 가능성이 있습니다.
합성 통제는 이러한 편향을 제거하기 위한 방법으로, 처치를 받지 않은 유사한 지역들을 찾아 개입 전후의 성과를 비교 기준으로 활용합니다. 이를 통해 North 지역에서 개입이 없었다면 발생했을 일일 매출 변화를 추정할 수 있으며, 보다 현실적인 기준선(baseline)을 구축할 수 있습니다.
단위 식별자(unit identifier)와 처치 대상 단위(treated unit)를 지정하고(나머지 단위는 합성 통제집단으로 사용됨), Synthetic Control 옵션을 선택한 후 CausalImpact 모델을 다시 실행합니다.
그 결과는 상당히 달라졌습니다. 다른 지역들의 개입 전후 추세를 통제한 결과, 상대적 증가율(relative lift)은 **37.5%**로 감소했습니다. 이는 처음 추정된 55.3%의 효과가 과대평가되었을 가능성을 시사합니다.


3. 추가 공변량(Covariates)
개입의 영향을 받지 않으면서 결과 변수의 변동성을 설명하는 공변량을 추가함으로써 모델을 더욱 개선할 수 있습니다.
이 예제에서는 마케팅 지출(marketing spend)을 공변량으로 포함했습니다. 하지만 결과는 거의 동일하게 나타났습니다. 이는 놀라운 결과가 아닙니다. 데이터 시뮬레이션 과정에서 마케팅 지출은 일일 매출과 상관관계가 없는 무작위 변수(random variable)로 생성되었기 때문입니다.

더 자세한 내용을 확인하려면 앱 내에서 다운로드할 수 있는 스크립트를 참고하시기 바랍니다.
import pandas as pd
import numpy as np
import dowhy
from dowhy import CausalModel
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from sklearn.linear_model import LinearRegression, LogisticRegression, LassoCV
from sklearn.preprocessing import StandardScaler
from econml.dml import LinearDML, CausalForestDML
from econml.metalearners import SLearner, TLearner
import matplotlib.pyplot as plt
import statsmodels.api as sm
from causalimpact import CausalImpact
# --- 1. Load Data ---
def simulate_bsts_demo_data():
"""Generates multi-region time series data for BSTS demo."""
np.random.seed(42)
regions = ['North', 'South', 'East', 'West']
total_days = 400
start_date = pd.to_datetime('2023-01-01')
date_range = pd.date_range(start=start_date, periods=total_days)
data_list = []
global_trend = np.linspace(100, 150, total_days)
weekly_seasonality = 10 * np.sin(2 * np.pi * np.arange(total_days) / 7)
monthly_seasonality = 20 * np.sin(2 * np.pi * np.arange(total_days) / 30)
for region in regions:
regional_trend = global_trend + np.random.normal(0, 10)
noise = np.random.normal(0, 5, total_days)
metric = regional_trend + weekly_seasonality + monthly_seasonality + noise
intervention_day = 300
if region == 'North':
lift = np.zeros(total_days)
lift[intervention_day:] = (
30 + np.cumsum(
np.random.normal(0.5, 0.1, total_days - intervention_day)
)
)
metric += lift
region_df = pd.DataFrame({
'Date': date_range,
'Region': region,
'Daily_Revenue': metric,
'Marketing_Spend': np.random.normal(50, 5, total_days),
'Is_Post_Intervention': (
np.arange(total_days) >= intervention_day
).astype(int),
'Is_Treated_Region': 1 if region == 'North' else 0
})
data_list.append(region_df)
return pd.concat(data_list, ignore_index=True)
df = simulate_bsts_demo_data()
print('Data Simulated Successfully')
# --- 3. Quasi-Experimental Analysis: CausalImpact ---
print("Running CausalImpact Analysis...")
from causalimpact import CausalImpact
date_col = 'Date' # Date
outcome_col = 'Daily_Revenue'
intervention_date = '2023-10-28' # Requires 'date' string
df[date_col] = pd.to_datetime(df[date_col])
# --- Prepare Time Series Data ---
# Panel Data Mode (Synthetic Control)
unit_col = 'Region'
treated_unit = 'North'
# 1. Pivot: Index=Date, Columns=Unit, Values=Outcome
df_pivot = df.pivot_table(
index=date_col,
columns=unit_col,
values=outcome_col,
aggfunc='sum'
)
# 2. Validate Treated Unit exists
if treated_unit not in df_pivot.columns:
raise ValueError(
f"Treated unit '{treated_unit}' not found in {unit_col} column."
)
# 3. Structure: Y (Treated) | X1, X2... (Controls)
# Move Treated Unit to first column (CausalImpact requirement)
cols = [treated_unit] + [
c for c in df_pivot.columns if c != treated_unit
]
df_final = df_pivot[cols]
# 4. Clean column names
df_final.columns = [str(c) for c in df_final.columns]
ts_data = df_final
ts_data = ts_data.asfreq('D').ffill()
# --- Run CausalImpact ---
pre_period = [
ts_data.index.min(),
pd.to_datetime(intervention_date) - pd.Timedelta(days=1)
]
post_period = [
pd.to_datetime(intervention_date),
ts_data.index.max()
]
# Robust Fallback for Index Handling
try:
ci = CausalImpact(ts_data, pre_period, post_period)
except KeyError:
# Fallback: Reset index to integer range if KeyErrors occur with DatetimeIndex
print("Fallback: Using Integer Index for CausalImpact...")
ts_data_reset = ts_data.reset_index(drop=True)
# Map dates to integer indices
pre_idx = [
0,
len(
ts_data.loc[
:pd.to_datetime(intervention_date) - pd.Timedelta(days=1)
]
) - 1
]
post_idx = [
pre_idx[1] + 1,
len(ts_data) - 1
]
# Rename columns to 0, 1, 2... for safety
ts_data_reset.columns = range(ts_data_reset.shape[1])
ci = CausalImpact(ts_data_reset, pre_idx, post_idx)
print(ci.summary())
ci.plot()
plt.show()V3의 기타 개선 사항
방법론의 특성을 기준으로, 더 나은 탐색 경험을 제공하기 위해 인과추론 기능을 두 개의 탭으로 구분했습니다.
관찰 분석(Observational Analysis): 횡단면 관찰 연구에 초점을 둡니다.
준실험 분석(Quasi-experimental Analysis): BSTS와 같은 시간에 따른 개입 전후 연구에 초점을 둡니다.
또한 각 방법론에 대한 학술 참고문헌을 추가하여, 사용자가 방법론을 더 자세히 이해하고자 할 때 원 논문을 참고할 수 있도록 했습니다. 사용자 가이드(User Guide) 탭에는 상세한 방법론 비교도 포함되어 있습니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 이미지를 클릭하세요.
마지막으로, 탐색적 분석(Exploratory Analysis) 탭도 개선했습니다. 여러 차원별로 차트를 분할할 수 있는 Facet 기능과 같은 고급 차트 빌더 기능을 추가했으며, 수치형 변수와 범주형 변수에 대한 데이터 요약도 자동화했습니다.
최신 앱은 아래 링크에서 확인할 수 있습니다. 사용해 보신 후 피드백을 남겨주시면 감사하겠습니다!
'실전에서 바로 쓰는 시계열 데이터 처리와 분석 in R' 카테고리의 다른 글
| 시계열의 테이블화: ML 기반 예측의 기초 (0) | 2026.06.18 |
|---|---|
| 시계열 예측에서 이상치를 다루는 실용 가이드: 탐지, 진단, 결정하기 (0) | 2026.05.30 |
| 시계열 예측에서 모든 데이터 과학자가 저지르는 10가지 실수와 해결 방법 (0) | 2026.05.30 |
| 세종 우수도서 선정! (0) | 2023.08.27 |
| 데이터홀릭 도서 증정 이벤트 (0) | 2021.10.29 |




댓글