수년 동안 외면했지만, 이제는 이것 없이 코딩할 수 없게 된 세 가지 패턴: Strategy, Repository, Observer.
저는 주니어 시절 대부분을 디자인 패턴은 소프트웨어 엔지니어들이 단순한 일을 복잡하게 만들기 위해 사용하는 것이라고 생각하며 데이터 과학 코드를 작성했습니다.
한 동료는 늘 패턴에 대해 이야기했습니다. 저는 고개를 끄덕였습니다. 그리고 다시 제 스크립트로 돌아갔습니다. 또 하나의 if/else 분기를 작성했습니다. 지금 생각하면 그 행동이 부끄럽습니다.
그러다 실제 모델을 프로덕션에 배포하는 팀에 합류하게 되었고, 처음으로 제대로 된 코드 리뷰를 받았습니다. 제 전처리 코드는 model_type에 따른 분기 로직이 네 개의 파일에 흩어져 있었습니다. 데이터 로딩 코드는 비즈니스 로직과 뒤엉켜 있었습니다. 학습 루프는 메트릭을 stdout에 출력하는 방식으로 기록하고 있었습니다. 리뷰어는 인내심이 있었지만, 저는 준비가 되어 있지 않았습니다.
그 코드 리뷰 이후 몇 달 동안 저는 디자인 패턴에 대해 훨씬 더 많은 것을 배우게 되었습니다. GoF를 공부했기 때문이 아닙니다. 각각의 패턴이 제가 부끄러워하던 문제를 해결해 주었기 때문입니다.
패턴 1: Strategy: 모델 유형에 따라 분기하지 마라

문제는 다음과 같은 형태였습니다.
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
import numpy as np
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])
def train(X, y, model_type: str):
if model_type == "rf":
model = RandomForestClassifier(n_estimators=100, random_state=42)
elif model_type == "gbm":
model = GradientBoostingClassifier(random_state=42)
elif model_type == "lr":
model = LogisticRegression(random_state=42)
else:
raise ValueError(f"Unknown model type: {model_type}")
model.fit(X, y)
return model
model = train(X, y, "rf")
print(type(model).__name__, model.predict([[3, 4]]))
RandomForestClassifier [1]
새로운 모델 변형을 추가할 때마다 이 함수를 수정해야 했습니다. 특정 모델을 테스트하고 싶을 때마다 문자열을 전달하고 올바른 분기를 탔기를 바랐습니다.
Strategy 패턴은 각 변형을 서로 교체 가능한 객체로 분리합니다.
from __future__ import annotations
from typing import Protocol
import numpy as np
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
class Classifier(Protocol):
def fit(self, X: np.ndarray, y: np.ndarray) -> None: ...
def predict(self, X: np.ndarray) -> np.ndarray: ...
def train(X: np.ndarray, y: np.ndarray, model: Classifier) -> Classifier:
model.fit(X, y)
return model
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 1, 0, 1])
rf = train(X, y, RandomForestClassifier(n_estimators=100, random_state=42))
gbm = train(X, y, GradientBoostingClassifier(random_state=42))
print(rf.predict([[3, 4]]))
print(gbm.predict([[3, 4]]))
[1]
[1]
이제 train 함수는 자신이 어떤 모델을 학습시키는지 알 필요가 없습니다. 새로운 모델 유형을 추가하는 것은 새로운 객체를 전달하는 것만으로 충분합니다. 따라서 train 함수를 수정할 필요도 없고, 새로운 분기를 추가할 필요도 없으며, 문자열 플래그를 사용할 필요도 없습니다.
scikit-learn의 추정기(estimator)는 덕 타이핑(duck typing)을 통해 이미 Classifier 인터페이스를 만족합니다. 이 패턴을 도입하는 데 드는 비용은 사실상 없었습니다.
패턴 2: Repository: 데이터 접근과 비즈니스 로직을 뒤섞지 마라
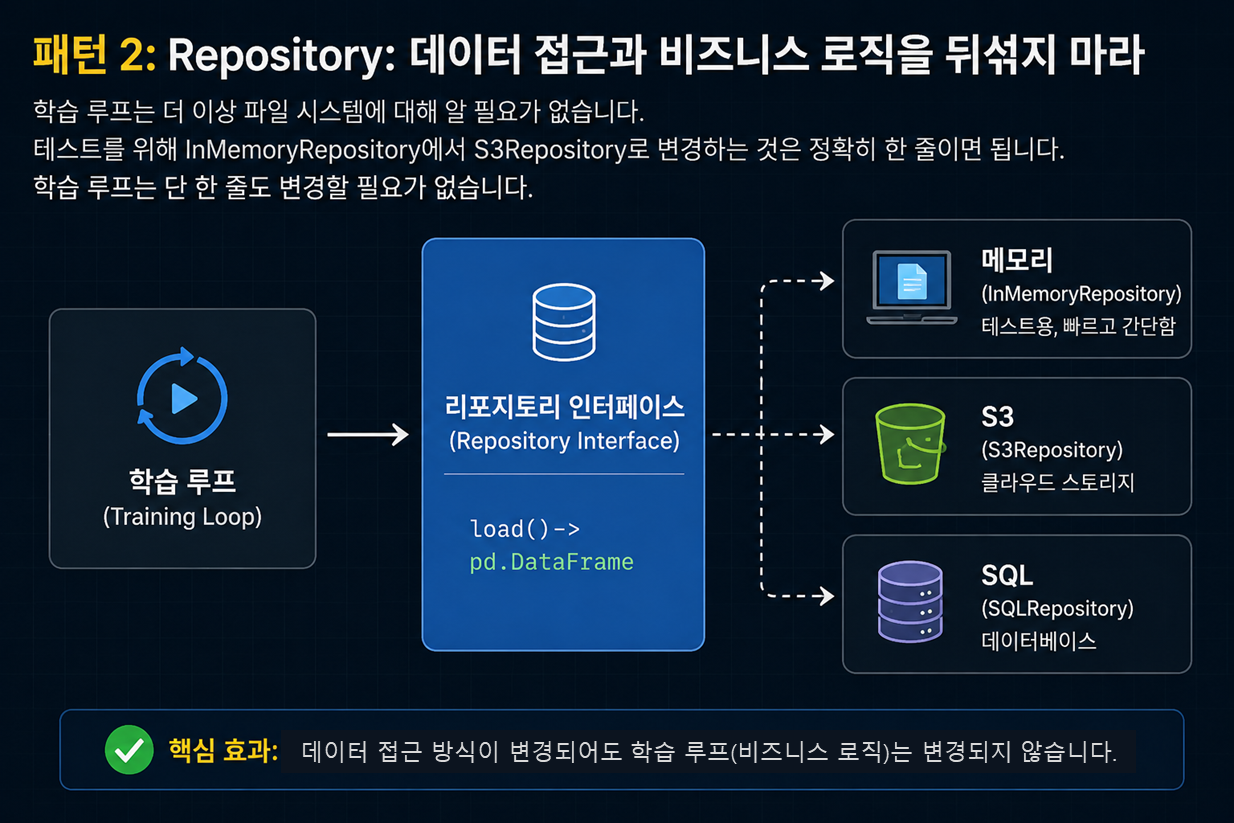
제 학습 루프는 데이터를 다음과 같이 불러왔습니다.
import pandas as pd
def load_training_data(source: str) -> pd.DataFrame:
if source == "local":
return pd.read_csv("data/train.csv")
elif source == "s3":
return pd.read_csv("s3://my-bucket/data/train.csv")
elif source == "db":
import sqlalchemy
engine = sqlalchemy.create_engine("postgresql://localhost/mydb")
return pd.read_sql("SELECT * FROM training_data", engine)
raise ValueError(f"Unknown source: {source}")
테스트를 하려면 실제 데이터베이스가 필요하거나 pd.read_sql을 모킹(mocking)해야 했습니다. 또한 학습 루프는 S3, Parquet, 로컬 CSV에 대한 내용을 동시에 알아야 했습니다.
Repository 패턴은 데이터 접근 앞에 단순한 인터페이스를 둡니다.
from __future__ import annotations
from typing import Protocol
import pandas as pd
class TrainingDataRepository(Protocol):
def load(self) -> pd.DataFrame: ...
class LocalCSVRepository:
def __init__(self, path: str) -> None:
self._path = path
def load(self) -> pd.DataFrame:
return pd.read_csv(self._path)
class InMemoryRepository:
"""테스트용 — 파일 시스템이 필요 없음."""
def __init__(self, df: pd.DataFrame) -> None:
self._df = df
def load(self) -> pd.DataFrame:
return self._df.copy()
def run_training(repo: TrainingDataRepository) -> None:
df = repo.load()
print(f"Loaded {len(df)} rows")
# ... 학습 로직
# 운영 환경 (data/train.csv가 존재해야 함):
# run_training(LocalCSVRepository("data/train.csv"))
# 테스트 — 파일 시스템 없이 실행 가능:
test_df = pd.DataFrame({"feature": [1, 2, 3], "label": [0, 1, 0]})
run_training(InMemoryRepository(test_df))
Loaded 3 rows
이제 학습 루프는 파일 시스템에 대해 알 필요가 없습니다. InMemoryRepository 덕분에 테스트는 매우 간단해졌습니다. 디스크도 필요 없고 네트워크도 필요 없으며 몇 밀리초 만에 실행됩니다.
우리가 S3로 이전했을 때는 S3Repository를 작성하고 조합(composition) 루트에서 한 줄만 변경하면 되었습니다. 학습 루프는 단 한 줄도 수정할 필요가 없었습니다.
패턴 3: Observer: 메트릭 로깅을 학습과 분리하라

stdout에 출력하는 방식으로 로그를 남기던 학습 루프는 다음과 같았습니다.
def train_epoch(model, X, y, epoch: int) -> float:
loss = round(0.9 ** epoch, 4) # 감소하는 loss를 시뮬레이션
print(f"Epoch {epoch}: loss={loss}")
return loss
for epoch in range(1, 4):
train_epoch(None, None, None, epoch)
Epoch 1: loss=0.9
Epoch 2: loss=0.81
Epoch 3: loss=0.729
팀이 MLflow를 도입했을 때, 누군가 학습 루프에 mlflow.log_metric을 추가했습니다. W&B 지원도 원하게 되자, 또 다른 분기가 추가되었습니다. 이제 학습 루프는 두 개의 추적 라이브러리를 import하고, 설정 플래그에 따라 조건부 로깅을 수행하게 되었습니다.
Observer 패턴은 메트릭을 발생시키는 부분과 메트릭을 소비하는 부분을 분리합니다.
from __future__ import annotations
from typing import Protocol
class MetricObserver(Protocol):
def on_epoch_end(self, epoch: int, metrics: dict) -> None: ...
class PrintObserver:
def on_epoch_end(self, epoch: int, metrics: dict) -> None:
print(f"Epoch {epoch}: " + ", ".join(f"{k}={v}" for k, v in metrics.items()))
class CSVObserver:
def __init__(self) -> None:
self._rows: list[dict] = []
def on_epoch_end(self, epoch: int, metrics: dict) -> None:
self._rows.append({"epoch": epoch, **metrics})
def rows(self) -> list[dict]:
return self._rows
def train_epoch(epoch: int, observers: list[MetricObserver]) -> None:
loss = round(0.9 ** epoch, 4) # 감소하는 loss를 시뮬레이션
for obs in observers:
obs.on_epoch_end(epoch, {"loss": loss})
csv_obs = CSVObserver()
for epoch in range(1, 4):
train_epoch(epoch, [PrintObserver(), csv_obs])
print("Recorded:", csv_obs.rows())
Epoch 1: loss=0.9
Epoch 2: loss=0.81
Epoch 3: loss=0.729
Recorded: [{'epoch': 1, 'loss': 0.9}, {'epoch': 2, 'loss': 0.81}, {'epoch': 3, 'loss': 0.729}]
MLflow를 추가한다는 것은 MLflowObserver를 작성하고 그것을 리스트에 추가한다는 의미입니다. 학습 루프는 단 한 줄도 변경되지 않습니다. 학습 루프는 학습에 관한 것입니다. 로깅은 다른 객체가 처리할 문제입니다.
이 세 가지의 공통점
각 패턴은 겉으로 보기에는 서로 다른 문제를 해결하지만, 그 밑에 있는 핵심 움직임은 같습니다. 변하는 부분을 변하지 않는 부분으로부터 분리하는 것입니다.
모델 변형은 바뀝니다. 학습 루프는 바뀌지 않습니다. → Strategy.
데이터 소스는 바뀝니다. 비즈니스 로직은 바뀌지 않습니다. → Repository.
로깅 대상은 바뀝니다. 학습 루프는 바뀌지 않습니다. → Observer.
타입 문자열에 따라 분기하거나, if source == "..." 조건문이 쌓이거나, 학습 루프가 추적 라이브러리를 import하고 있는 자신을 발견할 때마다 저는 이 패턴을 알아차립니다. 이 세 가지 중 하나가 들어맞습니다.
과거의 나에게 해주고 싶은 말
디자인 패턴을 “엔터프라이즈에서나 쓰는 것”이라고 치부했던 과거의 저에게 돌아가 말할 수 있다면 이렇게 말하고 싶습니다. 디자인 패턴은 엔터프라이즈에 관한 것이 아닙니다. 그것은 시스템의 변경 표면(change surface)에 관한 것입니다. GoF의 모든 패턴은 코드의 어떤 부분들이 서로 독립적으로 변경될 것으로 예상하는지에 대한 특정 질문의 답입니다.
데이터 과학에서 그 질문은 거의 항상 이것입니다. 파이프라인의 어떤 부분을 우리가 실험하고 있는가? 그 부분에는 이음새(seam)가 필요합니다. 패턴은 그 이음새를 제공합니다.
'데이터 사이언스 & 데이터 엔지니어링' 카테고리의 다른 글
| 2026년 모든 데이터 엔지니어가 반드시 알아야 할 12가지 데이터 아키텍처 패턴 (0) | 2026.06.27 |
|---|---|
| 피처 엔지니어링 완벽 가이드: Python 코드로 살펴보는 50가지 이상의 기법 (0) | 2026.06.10 |
| 피처 엔지니어링 입문: 스케일링, 정규화, 표준화를 쉽게 이해하기 (0) | 2026.05.30 |
| 데이터를 이동, 변환, 신뢰하는 방법에 대한 완전 가이드 (0) | 2026.05.27 |
| 데이터 과학자에서 AI 아키텍트로(From Data Scientist to AI Architect) (0) | 2026.05.19 |




댓글