LUVIT♥ EPL과 유튜브 데이터로 배우는 DuckDB | LUVIT(러빗) 시리즈 | 이기준
DuckDB를 활용한 SQL 기반 데이터 분석 입문서다. SQL 기초부터 고급 활용, 파이썬 연동, 데이터 시각화와 대시보드 제작까지 단계적으로 학습할 수 있다. EPL 데이터, 유튜브 트렌드, 「케이팝 데몬
www.aladin.co.kr
모두가 분산 컴퓨팅의 미래를 논쟁하는 동안, 하나의 바이너리가 실제로 여러분이 마주치게 될 대부분의 스택에서 대부분의 데이터 파이프라인을 위해 Spark 클러스터를 조용히 대체하고 있습니다.DuckDB: 소규모 Spark의 종말모두가 분산 컴퓨팅의 미래를 논쟁하는 동안, 하나의 바이너리가 실제로 여러분이 마주치게 될 대부분의 스택에서 대부분의 데이터 파이프라인을 위해 Spark 클러스터를 조용히 대체하고 있습니다.
Spark 작업 하나가 지금 이 순간에도 어딘가의 관리형 클러스터에서 실행되고 있습니다. 이 작업은 8GB의 Parquet 데이터를 읽고, 세 번의 집계를 수행한 뒤 결과 테이블을 저장합니다. 전체 실행 시간은 4분입니다. 그중 2분은 executor 협상, JVM 워밍업, 그리고 shuffle 준비 단계에 사용됩니다. 실제 계산은 30초도 채 걸리지 않습니다.
아무도 이를 문제 삼지 않습니다. 클러스터는 이미 존재하고 있었고, Spark는 표준이었기 때문입니다. 그래서 파이프라인은 그대로 유지됩니다.
이 글은 바로 그 결정, 그리고 그 결정을 다시 검토하지 않았을 때 발생하는 비용에 대한 이야기입니다.
시간을 낭비하게 만드는 반사적 선택
데이터 엔지니어들은 Spark를 초기에 배우고 거의 모든 곳에 적용합니다. 사고방식은 빠르게 굳어집니다. 대용량 데이터는 분산 컴퓨팅이 필요하고, 분산 컴퓨팅은 곧 Spark라는 생각입니다. 오랫동안 이 논리는 타당했습니다. 하지만 지금은 그 타당성이 점점 약해지고 있으며, 그 변화는 측정 가능한 수준에 이르렀습니다.
새로운 파이프라인을 만들기 전에 던져야 할 질문은 "이 작업을 Spark에서 어떻게 실행할까?"가 아닙니다. 올바른 질문은 "이 작업이 정말 클러스터를 필요로 하는가?"입니다.
대부분의 경우, 개발자 한 대의 머신에서 50GB 이하의 데이터를 처리하는 파이프라인이라면 솔직한 답은 "아니오"입니다. 클러스터는 JVM 오버헤드, executor 기동 지연, shuffle 준비 비용, 그리고 설정 복잡성을 추가합니다. 반면 하나의 바이너리 프로그램만으로도 몇 초 안에 끝낼 수 있는 작업인 경우가 많습니다. 엔지니어는 분산 환경의 세금을 지불하지만, 분산 환경의 이점을 얻지 못합니다.
물론 이 기준이 절대적인 법칙은 아닙니다. 16GB 메모리를 가진 노트북은 약 20GB 정도의 데이터에서 메모리 압박을 받기 시작합니다. 반면 128GB 메모리와 NVMe 임시 저장 공간을 갖춘 가상 머신은 100GB를 훨씬 넘는 데이터도 처리할 수 있습니다. 정확한 수치는 사용 중인 하드웨어에 따라 달라집니다. 하지만 원칙은 변하지 않습니다.
이 글은 두 가지를 다룹니다.
첫째, DuckDB가 소규모 및 중간 규모 데이터 처리에서 Spark보다 훨씬 뛰어난 성능을 보인다는 구체적인 증거를 살펴봅니다.
둘째, Parquet 데이터에서 시작하여 Iceberg 레이크하우스까지 이어지는 실제 ETL 파이프라인을 단 하나의 Python 프로세스와 클러스터 없이 구축하는 방법을 소개합니다.
그리고 Spark가 승리하는 영역에 대해서도 솔직하게 이야기합니다.
왜냐하면 실제로 그런 영역이 존재하기 때문입니다.
왜 DuckDB는 단일 머신에서 구조적으로 더 빠를까
벤치마크를 살펴보기 전에 먼저 이해해야 할 것은 사고방식입니다. 작동 원리에 대한 설명 없이 속도만 주장하는 것은 결국 마케팅에 불과합니다.
DuckDB는 서버가 아닙니다. 프레임워크도 아닙니다. 라이브러리입니다.
DuckDB는 Python 프로세스 내부, R 세션 내부, 혹은 명령행 환경 내부에서 직접 실행됩니다. 여러분의 코드와 쿼리 엔진 사이에 TCP 연결이 존재하지 않으며, 결과를 직렬화할 필요도 없고, 드라이버 프로토콜 오버헤드도 없습니다.
쿼리 엔진은 스크립트와 동일한 메모리 공간 안에서 동작합니다. 이 구조는 분산 시스템이 구조적으로 항상 부담해야 하는 지연 비용의 한 범주를 완전히 제거합니다.
아래 그림은 이러한 비용 차이가 정확히 어디에서 발생하는지를 보여줍니다.
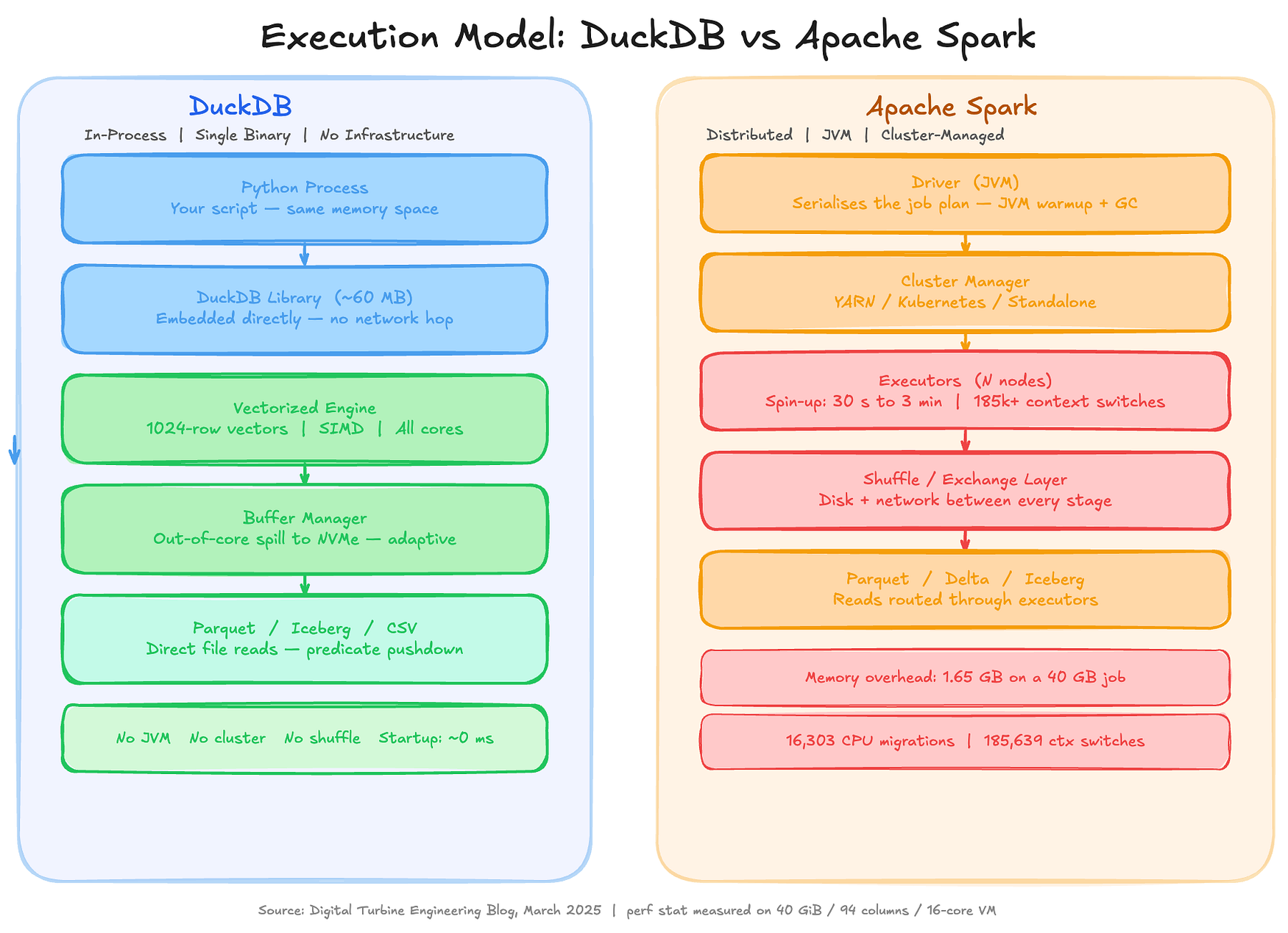
좌측은 DuckDB 아키텍처를 나타냅니다. DuckDB는 Python 프로세스 내부의 라이브러리로 실행되며 네트워크 경계가 존재하지 않습니다. 데이터는 벡터화 실행 엔진(Vectorized Engine), 버퍼 관리자(Buffer Manager)를 거쳐 Parquet 또는 Iceberg 파일에 직접 접근합니다.
우측은 Spark 아키텍처를 나타냅니다. Spark는 Driver JVM, 클러스터 매니저, 다수의 Executor, 그리고 Shuffle 계층을 거쳐 작업을 수행합니다.
빨간색 주석은 Digital Turbine이 2025년 3월에 수행한 perf stat 측정 결과를 나타내며, 총 185,639회의 컨텍스트 스위치와 16,303회의 CPU 마이그레이션이 발생했음을 보여줍니다.
쿼리 진입 지점부터 스토리지까지 전체 스택을 기준으로 비교한 인프로세스(In-Process) 실행 모델과 클러스터 실행 모델의 차이입니다.
DuckDB 측에는 실제 계산이 시작되기 전에 준비해야 할 이동 부품이 존재하지 않습니다.
반면 Spark 측에는 여러 단계의 준비 과정이 존재합니다.
엔진 자체의 구조
DuckDB는 벡터(vector)라고 불리는 컬럼 기반 배치 단위로 데이터를 처리합니다. 각 벡터는 대략 1,024개의 행으로 구성됩니다.
이 벡터 크기는 CPU 캐시 활용도를 최대화하도록 설계되어 있습니다. 덕분에 프로세서는 SIMD(Single Instruction, Multiple Data) 명령어를 사용하여 데이터를 행 단위가 아닌 전체 컬럼 단위로 한 번에 처리할 수 있습니다.
이러한 벡터화 실행(Vectorized Execution) 방식은 행 단위 처리 모델과 비교했을 때 캐시 지역성(cache locality)을 크게 향상시키고 메모리 접근 오버헤드를 줄여줍니다.
스레드 관리는 morsel-driven 모델을 따릅니다.
각 스레드는 입력 데이터의 자신만의 세그먼트를 처리하며, 자체적인 로컬 해시 테이블 또는 정렬된 실행 결과(sorted run)를 유지합니다. 계산이 수행되는 동안에는 락(lock) 경쟁이 발생하지 않습니다.
모든 스레드가 작업을 완료한 후에 결합(combine) 단계가 전체 CPU 코어에 걸쳐 실행됩니다.
그 결과 CPU 활용률은 극대화되며, 스레드 간 조정 비용은 사실상 0에 가깝습니다.
데이터 크기가 사용 가능한 RAM을 초과할 경우에는 DuckDB의 버퍼 관리자(Buffer Manager)가 디스크로 데이터를 적응적으로 스필(spill)합니다.
그룹화(Group By), 정렬(Sort), 조인(Join), 윈도 함수(Window Function) 모두 외부 메모리(out-of-core) 실행을 지원합니다.
Hannes Mühleisen은 2025년 PyData Amsterdam 행사에서 이를 직접 시연했습니다. 60억 개의 행을 포함하는 265GB 데이터셋에 대해 COUNT DISTINCT 연산을 수행했으며, 단 2GB의 메모리만 사용하여 46초 만에 작업을 완료했습니다.
클러스터는 필요하지 않았습니다.
Executor 협상 과정도 없었습니다.
일반적으로 시작 오버헤드는 무시할 수 있을 정도로 작습니다. 반면 Spark에서는 관리형 클러스터 환경에서 Executor 협상만으로도 수십 초에서 수분이 추가될 수 있습니다.
핵심 통찰은 다음과 같습니다.
DuckDB의 인프로세스(In-Process) 설계는 단순히 인프라 복잡성을 제거하는 것이 아닙니다.
Spark가 대규모 분산 처리의 대가로 당연하게 받아들이는 여러 종류의 지연(latency)을 구조적으로 제거합니다.
그리고 작업이 단일 머신에 충분히 들어가는 규모라면, 그 비용은 단순한 낭비에 불과합니다.
벤치마크 증거
데이터 없는 주장은 의견일 뿐입니다.
아래는 출처와 측정 방법이 명확하게 공개된 벤치마크 결과들입니다.
아래 표는 서로 다른 규모와 작업 유형을 대상으로 수행된 네 개의 독립적인 테스트 결과를 요약한 것입니다.
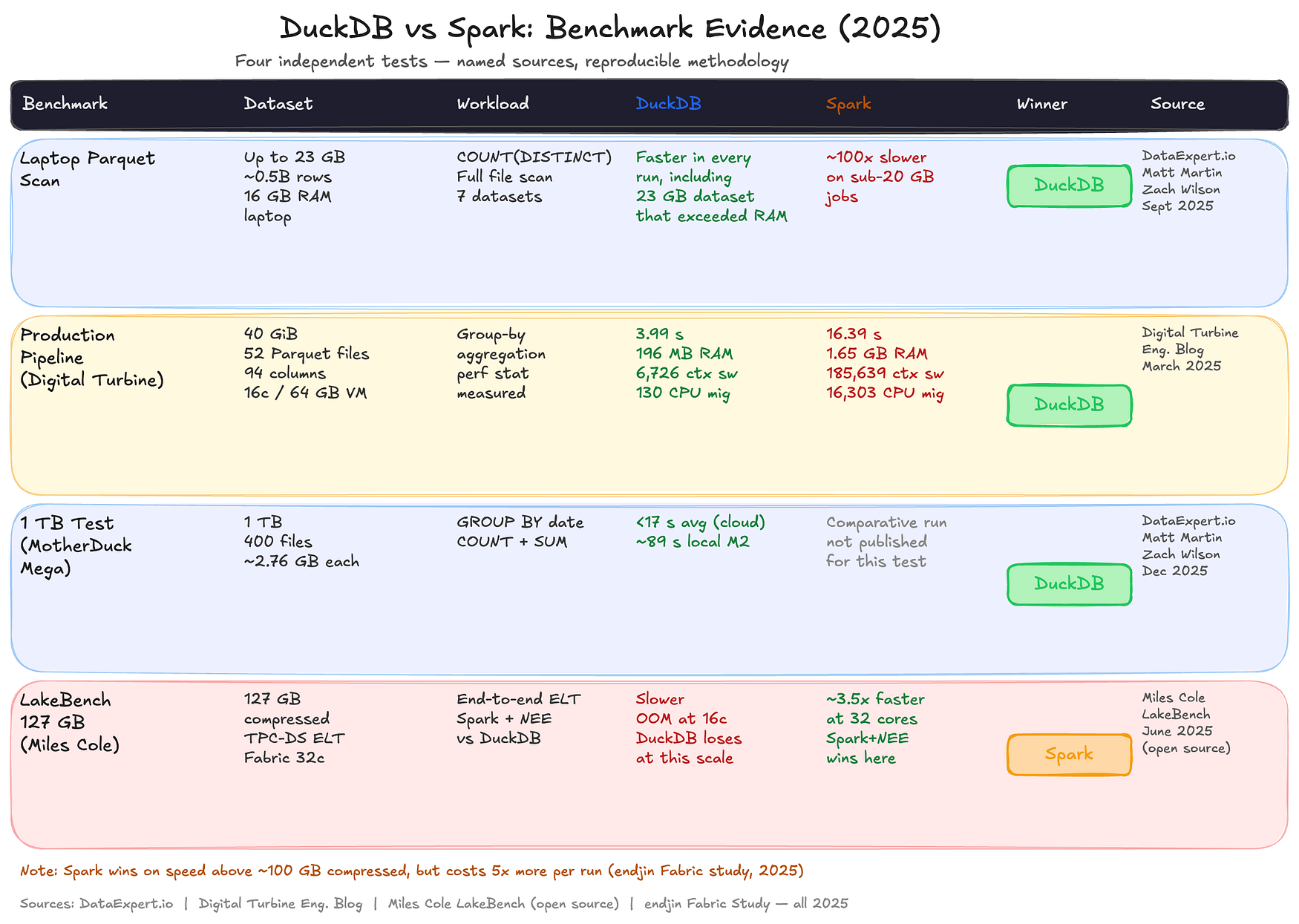
벤치마크 표는 다음과 같습니다.
1행: DataExpert.io, 최대 23GB 데이터, 16GB RAM 노트북, COUNT DISTINCT 작업. DuckDB가 최대 100배 빠름. DuckDB 승리.
2행: Digital Turbine, 40GiB 그룹화(Group By) 작업. DuckDB는 3.99초와 196MB 메모리를 사용했고, Spark는 16.39초와 1.65GB 메모리를 사용함. DuckDB 승리.
3행: DataExpert.io, MotherDuck Mega 환경에서 1TB 데이터 처리. 17초 미만으로 완료. DuckDB 승리.
4행: Miles Cole의 LakeBench 테스트, Microsoft Fabric 환경에서 127GB ELT 작업 수행. 32코어 환경에서 Spark가 3.5배 더 빠름. Spark 승리.
23GB부터 1TB까지 다양한 규모의 테스트에서 측정한 실행 시간(Wall-Clock Time), 최대 메모리 사용량(Peak Memory), 그리고 CPU 동작 특성을 비교한 결과입니다.
노트북 테스트: 20GB 이하 데이터에서 최대 100배
DataExpert.io의 Matt Martin과 Zach Wilson은 16GB RAM을 탑재한 노트북에서 DuckDB와 기본 Apache Spark를 비교하는 벤치마크를 수행했습니다.
테스트는 최대 23GB 크기의 7개 Parquet 데이터셋을 대상으로 진행되었습니다.
작업은 랜덤 문자열 컬럼에 대한 COUNT DISTINCT 연산이었습니다.
이 워크로드는 최적화 우회가 불가능하도록 설계되었으며, 전체 파일을 반드시 스캔해야 하는 조건을 강제했습니다.
결과는 매우 명확했습니다.
DuckDB는 모든 테스트에서 Spark보다 빠른 성능을 보였습니다.
심지어 머신의 RAM 용량을 초과하는 23GB 데이터셋에서도 DuckDB가 더 빨랐습니다.
이들이 공개한 결론은 다음과 같습니다.
테스트된 COUNT DISTINCT 워크로드 기준으로, DuckDB는 20GB 이하 데이터셋에서 Apache Spark보다 최대 약 100배 빠른 성능을 보였습니다.
Matt Martin이 이 벤치마크를 통해 정리한 실무 규칙은 다음과 같습니다.
기본 선택은 DuckDB입니다.
데이터가 16GB 메모리 환경에서 약 20GB를 초과하기 시작할 때 Spark를 고려합니다.
이는 절대적인 데이터 크기 제한이 아닙니다.
메모리 압박(memory pressure)이 발생하기 시작하는 임계점에 대한 경험적 기준입니다.
실제 운영 파이프라인: perf stat으로 측정한 결과
Digital Turbine 엔지니어링 팀은 2025년 3월, 단순한 실행 시간 측정을 넘어 Linux의 perf stat을 사용하여 CPU 동작까지 분석하는 보다 엄격한 테스트를 수행했습니다.
워크로드는 52개의 Parquet 파일과 94개 컬럼으로 구성된 총 40GiB 데이터에 대한 Group By 집계 작업이었습니다.
테스트 환경은 16코어 CPU와 64GB 메모리를 갖춘 클라우드 가상 머신이었습니다.
결과는 다음과 같았습니다.
DuckDB는 3.99초 만에 작업을 완료했습니다.
Spark는 16.39초가 걸렸습니다.
하지만 단순히 2.5배 빠르다는 사실보다 메모리와 CPU 지표가 더 많은 것을 말해줍니다.
DuckDB의 최대 RSS(Resident Set Size)는 196MB였습니다.
Spark는 1.65GB를 사용했습니다.
DuckDB는 6,726회의 컨텍스트 스위치와 130회의 CPU 마이그레이션을 발생시켰습니다.
반면 Spark는 185,639회의 컨텍스트 스위치와 16,303회의 CPU 마이그레이션을 발생시켰습니다.
이 수치들은 JVM 워밍업, 가비지 컬렉션, 그리고 실제로는 분산 처리가 필요하지 않은 작업에 분산 처리 중심 실행 계획이 적용되면서 발생한 비용을 보여줍니다.
결국 Digital Turbine은 해당 파이프라인을 DuckDB 기반 Kubernetes CronJob으로 교체했습니다.
기존 Spark 버전은 sbt 빌드 시스템을 사용하는 100줄 규모의 Scala 프로젝트였습니다.
교체된 DuckDB 버전은 단 6줄의 Python 코드와 pip install 하나로 구현되었습니다.
현실적인 한계: Spark가 다시 우위를 가져오는 구간
2025년 6월 공개된 Miles Cole의 Microsoft Fabric 기반 LakeBench 연구는 현재까지 가장 엄격하게 수행된 독립 벤치마크 중 하나이며, 기대치를 조정하는 데 가장 중요한 자료입니다.
연구 결과는 Spark와 DuckDB의 경계가 어디에 있는지를 명확하게 보여줍니다.
압축 기준 140MB와 1.2GB 규모에서는 단일 노드 엔진이 Spark를 명확하게 앞섰습니다.
12.7GB 규모에서는 Native Execution Engine이 적용된 Spark가 가장 빨랐지만 DuckDB 역시 경쟁력 있는 성능을 보였습니다.
그러나 압축 기준 127GB 규모에서는 상황이 달라졌습니다.
Spark는 코어 수에 따라 DuckDB보다 3.5배에서 6배 더 빠르게 실행되었습니다.
해당 테스트에서 DuckDB는 16코어 환경에서 메모리 부족(Out of Memory) 문제를 겪었습니다.
endjin이 수행한 Microsoft Fabric 병렬 연구는 여기에 비용 측면의 관점을 추가합니다.
흥미롭게도 Spark가 실행 시간에서 승리하는 구간에서도 가장 저렴한 Spark 실행 비용은 가장 저렴한 DuckDB 실행 비용보다 5배 이상 높았습니다.
즉, 속도와 비용은 서로 다른 문제이며, 두 질문의 답이 항상 일치하지는 않습니다.
현재까지의 증거는 비교적 명확한 기준점을 제시합니다.
표준적인 개발자 머신 환경에서 약 50GB 이하의 데이터라면 DuckDB가 속도, 비용, 운영 단순성 측면에서 우위를 가집니다.
압축 데이터 기준 약 100GB를 넘어가면 Native Vectorized Engine을 사용하는 Spark가 속도 측면에서 앞서기 시작합니다.
다만 그 대가로 훨씬 높은 인프라 비용을 지불해야 합니다.
그리고 그 사이 구간에서는 일반론보다 실제 데이터를 이용한 벤치마크가 가장 좋은 답입니다.
VS Code에서 환경 설정하기
설정은 5분도 걸리지 않습니다.
사실 그 자체가 이미 DuckDB를 선택해야 하는 이유 중 하나입니다.
uv로 설치하기
uv는 속도와 재현성을 중요하게 생각하는 엔지니어들 사이에서 사실상의 표준 Python 패키지 관리자입니다.
한 번 설치한 뒤 프로젝트를 초기화합니다.
# uv가 설치되어 있지 않다면 설치
curl -LsSf https://astral.sh/uv/install.sh | sh
# 프로젝트 생성
uv init duckdb-pipeline
cd duckdb-pipeline
# 의존성 추가
uv add duckdb pandas pyarrow
# 관리되는 환경에서 스크립트 실행
uv run any_script.py
JVM도 필요 없습니다.
클러스터 설정도 필요 없습니다.
Executor 메모리 튜닝도 필요 없습니다.
DuckDB는 약 60MB 크기에 외부 의존성이 전혀 없습니다.
uv는 몇 밀리초 만에 의존성을 해결하고 잠금(lock) 파일을 생성하며, uv run은 별도의 가상환경 활성화 과정 없이도 항상 올바른 버전의 패키지를 사용하도록 보장합니다.
VS Code 확장 프로그램
VS Code 마켓플레이스에서 ChuckJonas가 개발한 DuckDB 확장 프로그램을 설치합니다.
이 확장 프로그램은 다음 기능을 제공합니다.
- 실시간 쿼리 패널
- 스키마 브라우저
- Parquet 및 CSV 파일 미리보기
- 대용량 결과에 대한 서버 측 페이지네이션
스크립트를 작성하기 전에 .parquet 파일을 바로 열고 SQL을 실행할 수 있습니다.
탐색적 데이터 분석은 원래 이런 느낌이어야 합니다.
프로젝트 구조
깔끔한 DuckDB 프로젝트는 일반적으로 다음과 같은 구조를 가집니다.
duckdb-pipeline/
├── .venv/ # uv가 관리하는 가상환경
├── data/
│ ├── raw/
│ │ ├── sales.parquet # setup_a/generate_data.py가 생성
│ │ └── sales_incremental.parquet # setup_b/generate_incremental.py가 생성
│ └── processed/
│ └── sales_summary.parquet # setup_a/pipeline_local.py의 결과물
├── setup_a/ # 로컬 Parquet 파이프라인 (인프라 불필요)
│ ├── generate_data.py # 200만 건의 가상 판매 데이터 생성
│ ├── pipeline_local.py # 변환, 집계, 결과 저장
│ └── inspect_plan.py # EXPLAIN ANALYZE 실행 계획 확인
├── setup_b/ # Iceberg REST 카탈로그 파이프라인 (Docker 필요)
│ ├── generate_incremental.py # 20만 건의 증분 데이터 생성
│ ├── pipeline_iceberg.py # Iceberg 테이블 초기 적재
│ ├── merge_iceberg.py # MERGE INTO 업서트
│ └── timetravel_iceberg.py # 스냅샷 조회 및 Time Travel
├── sql/ # 재사용 가능한 SQL 변환 파일
├── pyproject.toml # uv가 관리하는 의존성 정의
└── uv.lock # 잠금된 의존성 그래프
운영 환경 가드레일(Production Guardrails)
대용량 데이터셋을 다루기 전에 반드시 명시적인 자원 제한을 설정해야 합니다.
DuckDB의 기본 설정은 의도적으로 관대한 편입니다.
따라서 매우 큰 조인(join) 결과에 대해 집계를 수행할 경우 아무 경고 없이 메모리를 모두 소진할 수 있습니다.
import duckdb
con = duckdb.connect("analytics.duckdb")
con.execute("SET memory_limit = '12GB'")
con.execute("SET temp_directory = '/tmp/duckdb_spill'")
con.execute("SET max_temp_directory_size = '50GB'")
con.execute("SET threads = 8") # 또는: SET threads = system_threads
con.execute("SET preserve_insertion_order = false")
memory_limit은 사용 가능한 RAM의 약 75% 수준으로 설정하는 것이 좋습니다.
temp_directory는 가장 빠른 디스크를 지정해야 합니다.
threads = 8은 여러 사용자가 함께 사용하는 시스템에서 안전한 기본값입니다.
전용 서버라면 다음 설정을 사용하는 것이 좋습니다.
SET threads = system_threads
이 설정을 사용하면 DuckDB가 사용 가능한 모든 CPU 코어를 자동으로 활용합니다.
이러한 가드레일은 대규모 작업 중 발생할 수 있는 메모리 부족 오류를 방지하고, 메모리가 부족할 경우 디스크 스필(spill)로 자연스럽게 전환되도록 만드는 핵심 설정입니다.
즉, 안정적으로 완료되는 작업과 중간에 실패하는 작업을 가르는 차이입니다.
실제 ETL 파이프라인: Parquet에서 Iceberg까지
이 섹션에는 완전히 실행 가능한 두 가지 예제가 포함되어 있습니다.
첫 번째는 로컬 환경에서만 동작하며 클라우드 인증 정보가 필요하지 않습니다.
두 번째는 DuckDB를 Apache Iceberg REST 카탈로그에 연결하고, MERGE INTO 업서트를 수행한 뒤, Time Travel 기능을 사용하여 스냅샷 이력을 조회합니다.
두 예제 모두 동일한 DuckDB 패턴을 사용합니다.
차이점은 데이터가 저장되는 위치와 DuckDB가 변경 사항을 커밋하는 방식뿐입니다.
Setup A: 로컬 Parquet 파이프라인
샘플 데이터 생성
# generate_data.py
import duckdb
con = duckdb.connect()
con.execute("""
COPY (
SELECT
(random() * 1000000)::INTEGER AS order_id,
['electronics','clothing','food','books'][
floor(random() * 4 + 1)::INTEGER] AS category,
['US','DE','FR','BR','JP'][
floor(random() * 5 + 1)::INTEGER] AS country,
(random() * 500 + 5)::DECIMAL(10,2) AS amount,
(random() * 0.3)::DECIMAL(5,4) AS discount_rate,
NOW() - INTERVAL (random() * 365) DAY AS order_date
FROM range(2000000)
)
TO 'data/raw/sales.parquet'
(FORMAT parquet, COMPRESSION zstd)
""")
con.close()
변환, 집계 및 저장
# pipeline_local.py
import duckdb
import time
con = duckdb.connect("analytics.duckdb")
con.execute("SET memory_limit = '12GB'")
con.execute("SET threads = 8")
start = time.perf_counter()
# DuckDB는 Parquet 파일을 직접 읽는다.
# 별도의 Import 단계가 필요 없다.
#
# 윈도 함수 참고:
# DuckDB는 OVER() 내부의 집계식을 GROUP BY가 완료된 후 평가한다.
# 따라서 RANK() 안의 SUM(amount)는 원본 행이 아니라
# category-country-month 단위로 집계된 결과를 의미한다.
con.execute("""
CREATE OR REPLACE TABLE sales_summary AS
SELECT
category,
country,
DATE_TRUNC('month', order_date) AS month,
COUNT(*) AS total_orders,
SUM(amount) AS gross_revenue,
SUM(amount * (1 - discount_rate)) AS net_revenue,
AVG(discount_rate) AS avg_discount,
RANK() OVER (
PARTITION BY category
ORDER BY SUM(amount) DESC
) AS revenue_rank
FROM read_parquet('data/raw/sales.parquet')
WHERE order_date >= CURRENT_DATE - INTERVAL 90 DAY
GROUP BY 1, 2, 3
""")
elapsed = time.perf_counter() - start
print(f"Transform complete in {elapsed:.3f}s")
# Zstandard 압축을 사용해 Parquet 저장
con.execute("""
COPY sales_summary
TO 'data/processed/sales_summary.parquet'
(FORMAT parquet, COMPRESSION zstd, ROW_GROUP_SIZE 100000)
""")
# 결과 검증
result = con.execute("""
SELECT category,
COUNT(DISTINCT country) AS markets,
SUM(net_revenue) AS total_net_revenue
FROM sales_summary
GROUP BY category
ORDER BY total_net_revenue DESC
""").fetchdf()
print(result)
con.close()
실행 계획 확인
운영 환경에 배포하기 전에 옵티마이저가 실제로 무엇을 수행하는지 반드시 확인해야 합니다.
con.execute("PRAGMA enable_profiling")
plan = con.execute("""
EXPLAIN ANALYZE
SELECT category, SUM(amount)
FROM read_parquet('data/raw/sales.parquet')
WHERE country = 'US'
GROUP BY category
""").fetchall()
for row in plan:
print(row[1])
실행 계획 하단에서 PARQUET_SCAN과 함께 Filters 주석이 표시되는지 확인합니다.
이는 필터가 모든 데이터를 읽은 후 적용되는 것이 아니라, 스캔 단계로 푸시다운(pushdown)되었음을 의미합니다.
Setup B: Iceberg REST Catalog 파이프라인
이 예제가 DuckDB의 활용 범위를 완전히 바꿔놓습니다.
DuckDB는 2025년 9월 공개된 v1.4.0 LTS부터 Apache Iceberg 테이블에 대해 완전한 ACID 쓰기를 지원합니다.
또한 2026년 5월 공개된 v1.5.3부터는 REST Catalog 기반 Iceberg 테이블에 대해 MERGE INTO 업서트도 지원합니다.
한 번 작성된 테이블은 Spark, Trino, Flink에서 즉시 읽을 수 있습니다.
계약(contract)은 엔진이 아니라 포맷입니다.
로컬 카탈로그 시작하기 (실습 환경)
# DuckDB Iceberg 테스트 스크립트 다운로드
git clone https://github.com/duckdb/duckdb-iceberg.git
cd duckdb-iceberg
# REST Catalog(8181)와 MinIO(9000) 실행
docker compose -f scripts/docker-compose.yml up -d
AWS 운영 환경에서는 아래 로컬 카탈로그 설정 대신 S3 Tables ARN을 사용하고, 수동 Secret 생성 대신 load_aws_credentials()를 사용합니다.
연결, 생성 및 초기 적재
# pipeline_iceberg.py
import duckdb
con = duckdb.connect()
con.execute("INSTALL iceberg; LOAD iceberg")
con.execute("INSTALL httpfs; LOAD httpfs")
# 로컬 MinIO 인증 정보
con.execute("""
CREATE OR REPLACE SECRET minio_secret (
TYPE s3,
KEY_ID 'admin',
SECRET 'password',
ENDPOINT '127.0.0.1:9000',
URL_STYLE 'path',
USE_SSL false
)
""")
# Iceberg REST Catalog 연결
con.execute("""
ATTACH '' AS lakehouse (
TYPE iceberg,
CLIENT_ID 'admin',
CLIENT_SECRET 'password',
ENDPOINT 'http://127.0.0.1:8181'
)
""")
con.execute("""
CREATE SCHEMA IF NOT EXISTS
lakehouse.analytics
""")
con.execute("""
CREATE TABLE IF NOT EXISTS
lakehouse.analytics.sales_summary (
category VARCHAR,
country VARCHAR,
month TIMESTAMP,
total_orders BIGINT,
net_revenue DECIMAL(18,2)
)
""")
# Parquet 데이터 초기 적재
con.execute("""
INSERT INTO lakehouse.analytics.sales_summary
SELECT
category,
country,
DATE_TRUNC('month', order_date) AS month,
COUNT(*) AS total_orders,
SUM(amount * (1 - discount_rate)) AS net_revenue
FROM read_parquet('data/raw/sales.parquet')
GROUP BY 1, 2, 3
""")
print("Initial load complete")
MERGE INTO를 이용한 업서트
# 증분 데이터 준비
con.execute("""
CREATE OR REPLACE TEMP TABLE incremental AS
SELECT
category,
country,
DATE_TRUNC('month', order_date) AS month,
COUNT(*) AS total_orders,
SUM(amount * (1 - discount_rate)) AS net_revenue
FROM read_parquet('data/raw/sales_incremental.parquet')
GROUP BY 1, 2, 3
""")
con.execute("""
MERGE INTO lakehouse.analytics.sales_summary AS target
USING incremental AS source
ON target.category = source.category
AND target.country = source.country
AND target.month = source.month
WHEN MATCHED THEN
UPDATE SET
total_orders = target.total_orders + source.total_orders,
net_revenue = target.net_revenue + source.net_revenue
WHEN NOT MATCHED THEN
INSERT (
category,
country,
month,
total_orders,
net_revenue
)
VALUES (
source.category,
source.country,
source.month,
source.total_orders,
source.net_revenue
)
""")
print("Upsert complete")
Time Travel 및 스냅샷 조회
Iceberg는 모든 커밋을 변경 불가능한 스냅샷으로 저장합니다.
각 스냅샷은 다음 정보를 가집니다.
- snapshot_id : 커밋 시 생성되는 고유 식별자
- sequence_number : 증가하는 버전 번호
- timestamp_ms : 커밋 시각
Time Travel은 잘못된 적재를 분석하거나, MERGE 전 상태를 확인하거나, 실수로 삭제한 데이터를 복구하는 핵심 기능입니다.
snapshots = con.execute("""
SELECT *
FROM iceberg_snapshots(
'lakehouse.analytics.sales_summary'
)
""").fetchdf()
print(
snapshots[
["sequence_number",
"snapshot_id",
"timestamp_ms"]
]
)
업서트 이전 상태 조회:
first_snapshot = (
snapshots
.sort_values("sequence_number")
["snapshot_id"]
.iloc[0]
)
historical = con.execute(f"""
SELECT
category,
SUM(net_revenue) AS revenue
FROM lakehouse.analytics.sales_summary
AT (VERSION => {first_snapshot})
GROUP BY category
ORDER BY revenue DESC
""").fetchdf()
print("State before upsert:")
print(historical)
con.close()
이것으로 객체 스토리지 위의 공유 Iceberg 테이블에 대해 ACID 커밋, 스냅샷 이력 관리, Time Travel을 지원하는 완전한 증분 파이프라인이 완성됩니다.
그리고 이 모든 작업은 단 하나의 Python 프로세스에서 수행됩니다.
클러스터는 필요하지 않습니다.
생성된 테이블은 모든 Iceberg 호환 엔진에서 즉시 읽을 수 있습니다.
여기까지 오는 데 Spark는 필요하지 않았습니다.
Spark가 여전히 우위를 가지는 영역
이 주장에도 한계는 있습니다.
그 사실을 명확히 인정하는 것이 실무자의 관점과 단순한 제품 홍보를 구분하는 기준입니다.
아래 의사결정 프레임워크는 데이터 규모와 운영 요구사항을 기준으로 어떤 도구를 선택해야 하는지를 보여줍니다.

의사결정 카드는 세 개의 영역으로 구성됩니다.
DuckDB (파란색)
대략 100MB ~ 100GB 규모
다음과 같은 경우에 적합합니다.
- 개인 개발자 파이프라인
- 애드혹(Ad-hoc) 분석 쿼리
- Parquet 및 Iceberg 기반 ELT
- 비용에 민감한 작업
둘 다 평가 (주황색)
약 10GB ~ 130GB 규모
이 구간에서는 실제 데이터로 벤치마크를 수행하고 비용까지 함께 비교해야 합니다.
Apache Spark (빨간색)
100GB 이상 규모 또는 다음 요구사항이 있는 경우
- 다중 노드 장애 복구
- 탄력적 확장(Elastic Scaling)
- Kafka Structured Streaming
이 기준은 DataExpert.io, LakeBench, endjin의 2025년 벤치마크 결과를 기반으로 정리되었습니다.
Spark가 승리하는 경우는 크게 네 가지입니다.
데이터가 실제로 단일 머신의 한계를 넘는 경우
DuckDB는 단일 노드 엔진입니다.
수 TB 규모의 데이터가 여러 스토리지 노드에 분산되어 있고, 작업 수행을 위해 다중 노드 셔플이 필요하다면 DuckDB는 이를 처리할 메커니즘이 없습니다.
반면 Spark는 바로 이러한 문제를 해결하기 위해 설계되었습니다.
노드 단위 장애 복구가 필요한 경우
DuckDB 작업이 실패하면 전체 작업이 실패합니다.
Spark는 작업 계보(Task Lineage)를 유지하며 체크포인트 이후부터 실패한 작업을 재실행할 수 있습니다.
Spot 인스턴스나 선점형(Preemptible) 컴퓨팅 환경에서 장시간 실행되는 작업이라면 이러한 복원력은 실제 운영상 큰 가치를 가집니다.
실시간 이벤트 스트림을 처리해야 하는 경우
DuckDB는 파일과 테이블을 처리합니다.
반면 Spark Structured Streaming은 Kafka 토픽을 직접 소비하며 정확히 한 번(Exactly-Once) 처리와 상태 기반 윈도 연산을 지원합니다.
이들은 본질적으로 다른 문제를 해결하는 도구입니다.
DuckDB를 아무리 최적화하더라도 이러한 차이는 사라지지 않습니다.
이미 Native Vectorized Engine 기반 Spark 환경을 사용 중인 경우
Databricks Photon과 Microsoft Fabric Native Execution Engine은 일반 Spark가 소규모 데이터에서 느린 이유 중 하나인 JVM 오버헤드의 대부분을 제거합니다.
Miles Cole의 LakeBench 연구에서는 다음 결과가 확인되었습니다.
- 12.7GB 데이터에서는 Spark + NEE가 가장 빠름
- 127GB 데이터에서는 Spark가 DuckDB보다 3.5배 빠름
이미 이러한 엔진 비용을 지불하고 있는 조직이라면 10GB 이상의 데이터 구간에서는 일반 Spark 벤치마크에서 보이는 격차보다 실제 차이가 훨씬 작을 수 있습니다.
데이터 크기 기준은 절대적인 숫자가 아닙니다.
16GB 노트북에서는 DuckDB의 실질적인 한계가 약 20GB 정도입니다.
128GB RAM과 NVMe 임시 저장소를 갖춘 VM에서는 압축 데이터 기준 100GB를 훨씬 넘어서도 처리할 수 있습니다.
중요한 신호는 데이터 크기가 아닙니다.
다음 상황이 발생할 때가 전환 시점입니다.
- 중간 결과가 지속적으로 RAM 크기를 초과하는 경우
- 디스크 스필이 과도하게 발생하는 경우
- 작업이 실제로 다중 노드 분산 처리를 필요로 하는 경우
실수는 Spark를 사용하는 것이 아닙니다.
실수는 작업이 정말 Spark를 필요로 하는지 묻지 않고 Spark를 선택하는 것입니다.
여러분이 되어가고 있는 엔지니어
DuckDB를 단순히 로컬 개발용 편의 도구로 보는 시각도 있습니다.
하지만 그 관점은 2025년과 2026년에 일어난 변화를 놓치고 있습니다.
DuckDB는 이제 Iceberg 쓰기를 지원합니다.
즉, Spark, Trino, Flink가 읽을 수 있는 테이블을 직접 생성할 수 있습니다.
클러스터 없이도 S3 기반 공유 레이크하우스에서 MERGE INTO 업서트를 수행할 수 있습니다.
Python 스크립트만으로 스냅샷 이력을 조회하고 원하는 시점으로 Time Travel을 수행할 수 있습니다.
실제 사례도 존재합니다.
- Watershed는 운영 환경에서 매일 75,000건의 DuckDB 쿼리를 처리합니다.
- Okta는 AWS Lambda 상에서 여러 DuckDB 인스턴스를 활용해 1억 3천만 개 파일, 7조 5천억 건의 레코드를 처리했습니다.
- 일일 처리량은 1.5TB에서 50TB까지 증가했습니다.
- Digital Turbine은 100줄짜리 Scala 프로젝트를 6줄의 Python 코드로 대체했습니다.
핵심은 개방형 포맷(Open Format)입니다.
포맷이 계약(contract)이고, 엔진은 워크로드에 따라 선택하는 구현체일 뿐입니다.
이번 주에 여러분의 환경에서 가장 작은 정기 Spark 작업 세 개를 찾아보십시오.
실제 데이터 크기와 실제 실행 비용을 확인해 보십시오.
만약 그중 하나라도 50GB 이하라면 동일한 변환 작업을 DuckDB로 로컬에서 실행해 보십시오.
직접 측정한 결과가 어떤 도구를 선택해야 하는지 명확하게 보여줄 것입니다.
더 중요한 변화는 질문 자체에 있습니다.
워크로드에 적합한 컴퓨팅 계층을 선택하는 것은 단순한 성능 최적화가 아닙니다.
그것은 기본적인 엔지니어링 판단입니다.
10GB 작업에 클러스터를 사용하는 것이 틀린 것은 아닙니다.
다만 문제보다 더 무거운 도구를 들고 있는 것뿐입니다.
여러분은 이제 도구를 선택하기 전에 먼저 올바른 질문을 던지는 엔지니어가 되어가고 있습니다.
이 작업은 정말 클러스터가 필요한가?
대부분의 경우, 그리고 여러분이 앞으로 마주하게 될 대부분의 데이터 파이프라인에서 그 답은 아니오입니다.
그리고 그 답이 아니오일 때 선택하는 도구가 바로 DuckDB입니다.
<출처: https://medium.com/towards-data-engineering/duckdb-the-death-of-small-scale-spark-e86ac6aedf23>
'EPL과 유튜브 데이터로 배우는 DuckDB' 카테고리의 다른 글
| DuckDB를 활용한 서버리스 RAG: AI 파이프라인의 단순화 (0) | 2026.06.15 |
|---|---|
| AI 우선 분석을 위한 DuckDB 확장 (0) | 2026.06.14 |
| DuckDB 쿼리 계획: EXPLAIN을 사용해 디버거처럼 조인 문제 수정 (0) | 2026.06.14 |
| 2026년 데이터 분석가를 위한 완전한 SQL 로드맵 (0) | 2026.06.14 |
| SQL을 쉽게 배우기: 데이터 과학자를 위한 입문 가이드 (0) | 2026.06.14 |




댓글