https://2stndard.tistory.com/notice/203
[발간예정][EPL과 유튜브로 배우는 DuckDB] 실습 코드와 데이터
EPL과 유튜브 데이터로 배우는 DuckDB에서 사용되는 실습 데이터와 코드를 제공합니다. EPL_DATA&samplefile.zip : 책에서 사용하는 영국 프리미어리그 데이터 셋과 샘플로 사용하는 파일espn.duckdb.zip : 책
2stndard.tistory.com
TL;DR: 이제 DuckDB 인스턴스끼리 Quack 원격 프로토콜(Remote Protocol) 을 통해 서로 통신할 수 있습니다. 이를 통해 DuckDB를 클라이언트-서버(Client–Server) 구조로 운영하면서 여러 사용자가 동시에 데이터를 기록(concurrent writes) 할 수 있게 되었습니다.
DuckDB 철학에 맞게 Quack은 설정이 간단하며, HTTP와 같은 검증된 기술을 기반으로 구축되었습니다. 또한 성능도 뛰어나 대량 데이터 처리(Bulk Operations) 부터 작은 규모의 트랜잭션 처리까지 다양한 워크로드를 지원합니다.
배경: 데이터베이스 아키텍처
데이터베이스가 처음 등장했을 때는 ‘클라이언트(Client)’와 ‘서버(Server)’를 구분하는 개념 자체가 없었습니다. 데이터베이스 전체가 하나의 컴퓨터에서 실행되었습니다.
1980년대쯤, Sybase가 처음으로 데이터베이스 서버와 클라이언트가 서로 다른 컴퓨터에서 동작하는 구조를 도입했습니다. 이후부터는 거의 모든 데이터베이스 시스템이 클라이언트-서버 아키텍처와 이를 연결하는 통신 프로토콜을 사용하는 것이 당연한 전제가 되었습니다.
이 방식은 편리했습니다. 변경 가능한 상태(mutable state)를 서버 한 곳에서 관리할 수 있고, 동시에 여러 클라이언트가 데이터를 읽고 쓰는 것이 가능했기 때문입니다.
물론 단점도 있습니다. 대표적으로 클라이언트와 서버 사이의 통신 프로토콜 자체가 상당한 오버헤드를 추가할 수 있다는 점입니다. (더 궁금하다면 DuckDB 팀이 이전에 데이터베이스 프로토콜에 관한 연구 논문도 발표했습니다.)
물론 클라이언트-서버 아키텍처에 반대하는 흐름도 항상 존재했습니다. 대표적인 사례가 2000년에 등장한 SQLite, 그리고 2019년에 처음 공개된 DuckDB입니다.
DuckDB는 그동안 인프로세스(In-Process) 아키텍처를 구현한 점을 적극적으로 강조해 왔습니다. 이는 클라이언트도 없고, 서버도 없으며, 별도의 통신 프로토콜도 없이 단순히 저수준 API 호출만 사용하는 구조입니다.
이 방식은 특히 데이터 과학(Data Science) 과 같은 인터랙티브한 활용 사례에서 매우 좋은 성능과 사용성을 보여주었습니다. 예를 들어 분석가가 Python 노트북 환경에서 데이터를 분석할 때, 같은 프로세스 내부에서 실행 중인 DuckDB 인스턴스가 데이터를 직접 관리하며 분석 작업이 이루어지는 방식입니다.
또한 DuckDB를 기존 애플리케이션에 붙여 넣듯(glued) 통합하여, 애플리케이션 내부 데이터에 SQL 기능만 추가하는 다양한 활용 사례에서도 매우 효과적으로 동작했습니다.
하지만 인프로세스(In-Process) 시스템은 여러 프로세스가 동시에 하나의 데이터베이스 파일을 수정해야 하는 상황에서는 상대적으로 적합하지 않습니다.
이러한 요구는 실제로 매우 흔합니다. 예를 들어, 여러 프로세스가 동시에 텔레메트리(telemetry) 데이터를 수집하여 하나의 데이터베이스에 기록하고 동시에 같은 테이블을 조회해 대시보드를 실시간으로 구동하는 상황 같은 경우입니다.
DuckDB가 이런 시나리오를 지원하지 못했던 데에는 충분한 기술적 이유가 있습니다.
가장 중요한 이유는 DuckDB가 다양한 상태(state) 정보를 메인 메모리에 유지하는 구조이기 때문입니다. 만약 여러 프로세스가 동시에 데이터 변경 작업을 시작하면, 이 메모리 상태들을 서로 동기화(synchronize) 해야 합니다.
이러한 상태 동기화는 구현 난이도가 높고 비용도 크기 때문에, 기존의 인프로세스 아키텍처에서는 자연스럽게 여러 프로세스의 동시 쓰기 작업을 지원하기 어려웠습니다.
물론 이를 해결하기 위한 우회 방법(workarounds) 은 존재했습니다.
가장 단순한 방법은 직접 RPC(Remote Procedure Call) 구조를 만드는 것입니다. 즉, 하나의 프로세스가 DuckDB 인스턴스를 보유하고 다른 프로세스들에게 조회(Query)와 데이터 삽입(Insert) 서비스를 제공하는 방식입니다.
또한 이미 여러 프로젝트들이 DuckDB에 클라이언트-서버 기능을 덧붙이는(retrofit) 시도를 해왔습니다. 대표적으로 Arrow Flight SQL 프로토콜을 활용하는 방식이 있습니다.
MotherDuck 역시 자체적으로 설계한 클라이언트-서버 프로토콜을 사용하고 있습니다.
그리고 물론 (조금 과장해서 말하자면) 기존의 전통적인 클라이언트-서버 데이터베이스로 갈아타는 방법도 있습니다. 대표적인 예가 널리 사용되는 PostgreSQL입니다.
더 나아가 PostgreSQL 위에서 DuckDB를 실행하는 이른바 “EleDucken” 구조도 사용할 수 있습니다.
이는 DuckDB를 PostgreSQL 내부에 통합하여 실행하는 방식이며, 이를 가능하게 하는 여러 확장(extension)이 존재합니다. 예를 들어 pg_duckdb 같은 프로젝트가 있습니다.
사람들이 DuckDB에 클라이언트-서버 기능을 덧붙이기 위해 만들어낸 수많은 우회 방법들은 적어도 한 가지 사실을 분명하게 보여주었습니다.
사용자들이 이 기능을 정말 원하고 있었다는 것입니다.
DuckDB는 스스로를 범용 데이터 처리(Data Wrangling) 도구라고 생각합니다.
만약 이를 위해 기존의 인프로세스 기능에 더해 클라이언트-서버 프로토콜까지 제공해야 한다면, 그것도 괜찮습니다.
그리고 그것이 DuckDB가 활용될 수 있는 완전히 새로운 사용 사례들을 열어준다면, 더할 나위 없이 좋은 일입니다.
결국 DuckDB 팀이 중요하게 생각하는 것은 아키텍처 논쟁에서 마지막 말을 남기는 것보다 사용자 경험(User Experience) 입니다.
그래서 결국 결정을 내렸고, 결과를 매우 기쁜 마음으로 발표합니다:
DuckDB를 위한 Quack 프로토콜 소개
두 마리(또는 그 이상)의 오리가 서로 대화하려면 어떻게 할까요?당연히 꽥(Quack) 소리를 냅니다.
그래서 두 개의 DuckDB 인스턴스가 서로 통신하는 프로토콜의 이름도 자연스럽게 “Quack” 이 되었습니다.
2026년의 DuckDB 팀은 기존 시스템과의 호환성(레거시)을 고려하지 않고 데이터베이스 프로토콜을 처음부터 새롭게 설계할 기회를 얻었습니다.
그 과정에서 기존 데이터베이스 프로토콜들뿐 아니라 비교적 최근의 Arrow Flight SQL 같은 사례들도 참고하며 장점을 학습할 수 있었습니다.
Quack이 내부적으로 어떻게 동작하는지 살펴보기 전에, 먼저 사용자 입장에서 Quack이 어떻게 사용되는지 보겠습니다.
우선 두 개의 DuckDB 인스턴스가 필요합니다.
맞습니다. 이제 DuckDB는 클라이언트 역할과 서버 역할을 모두 수행할 수 있습니다.
이 두 인스턴스는 지구 반대편에 있는 서로 다른 컴퓨터일 수도 있고 (심지어 우주에 있어도 되고), 아니면 내 노트북에서 실행 중인 두 개의 터미널 창일 수도 있습니다.
먼저 두 DuckDB 인스턴스 모두에 Quack 확장(extension) 을 설치해야 합니다.
현재 Quack은 core_nightly 저장소에서 제공되고 있으며, 현재 릴리스 버전인 DuckDB v1.5.2 에서 사용할 수 있습니다.

그러면 DuckDB #2에 있는 원격 테이블 hello, world의 내용이 표시됩니다. 마치 마법 같죠!
또한 로컬 인스턴스의 데이터를 원격 인스턴스로 복사할 수도 있습니다.
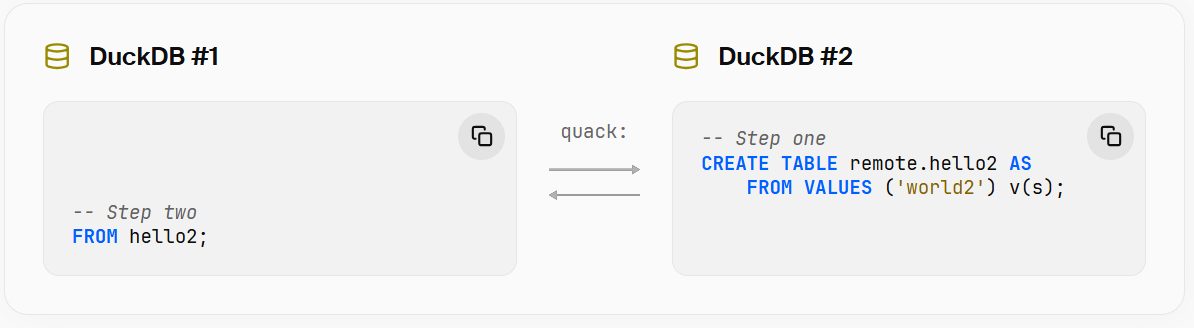
마찬가지로 이번에는 DuckDB #1의 출력에서 world2가 표시되는 것을 확인할 수 있어야 합니다.
물론 지금까지의 예시는 가장 단순한 수준의 예제일 뿐입니다.
실제 환경에서는 테이블 구조가 훨씬 더 복잡할 수 있고, 쿼리 역시 훨씬 복잡해질 수 있으며, 처리해야 하는 데이터 규모도 매우 클 수 있습니다(아래에서 더 자세히 다룹니다).
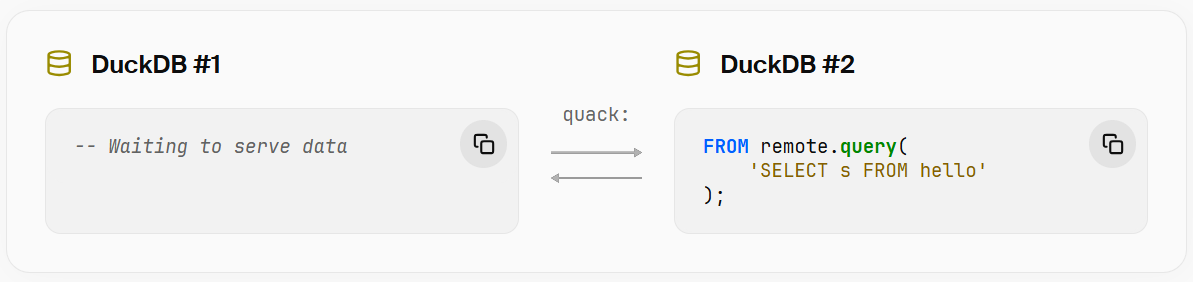
또한 query 함수를 사용하면 전체 SQL 쿼리를 그대로(verbatim) 원격 인스턴스로 전달하여 실행할 수도 있습니다.
이 방식은 특히 대규모 데이터셋에 대한 매우 복잡한 쿼리를 실행할 때, 어떤 작업을 원격 환경에서 수행할지 더 세밀하게 제어하고 싶을 때 더 적합한 방법입니다.
프로토콜 설계
HTTP 기반
Quack은 오랜 역사를 가진 HTTP(Hypertext Transfer Protocol) 를 기반으로 구축되었습니다.
CERN에서 시작된 HTTP는 이제 사실상 TCP와 그 아래 네트워크 계층 위에서 동작하는 표준 프로토콜 계층(de-facto protocol layer) 이 되었습니다. 오늘날 네트워크 스택 전체는 HTTP 메시지 스트림을 효율적으로 전송하도록 최적화되어 있습니다.
또한 HTTP는 제대로 구현하면 생각보다 오버헤드가 매우 낮습니다.
게다가 거의 모든 사람들이 HTTP를 다루는 방법을 알고 있습니다.
예를 들어 로드 밸런싱(Load Balancing), 인증(Authentication), 방화벽(Firewalls), 침입 탐지(Intrusion Detection), 기타 네트워크 운영 환경과 같은 인프라 영역에서 이미 성숙한 생태계를 갖추고 있습니다.
그래서 2026년에 새로운 데이터베이스 프로토콜을 설계하면서 HTTP 위에 구축하지 않는 것이 오히려 비합리적일 수 있다고 DuckDB 팀은 판단했습니다.
또 하나의 큰 장점은 HTTP 덕분에 DuckDB-Wasm 배포판도 Quack을 네이티브하게 사용할 수 있다는 점입니다.
즉, 브라우저 안에서 실행되는 DuckDB가 직접 Quack 프로토콜을 통해 원격 DuckDB 인스턴스와 통신할 수 있습니다.
예를 들어 브라우저에서 실행 중인 DuckDB-Wasm, AWS EC2 서버에서 실행 중인 DuckDB 인스턴스 등이 Quack을 이용해 직접 연결되는 구조가 가능해집니다.
요청–응답(Request–Response) 패턴
Quack에서의 모든 상호작용은 클라이언트가 시작하는 요청–응답(Request–Response) 방식으로 동작합니다.
예를 들어 Quack 메시지에는 연결(Connection) 요청, 토큰(Token)을 이용한 인증(Authentication) 요청, 쿼리 실행 요청, 응답 결과의 첫 번째 일부를 반환하는 메시지, 큰 결과 집합을 이어서 가져오기 위한 후속 Fetch 요청 등이 포함됩니다.
특히 대용량 결과를 처리할 때는 여러 스레드가 병렬로 Fetch 요청을 보내 결과를 가져오는 방식도 지원됩니다.
(인증(Authentication) 및 권한 부여(Authorization)에 대한 자세한 내용은 아래에서 별도로 설명합니다.)
직렬화(Serialization)
Quack의 요청(Request)과 응답(Response)은 새로운 MIME 타입인 application/duckdb 형식으로 인코딩됩니다.
이 인코딩 방식은 DuckDB 내부에서 이미 사용 중인 고성능 직렬화(serialization) 기능을 활용합니다.
특히 데이터 타입(Data Types) , 쿼리 결과(Result Sets)와 같은 복잡한 구조를 효율적으로 직렬화할 수 있습니다.
흥미로운 점은 DuckDB가 이러한 직렬화 기능을 이미 수년 동안 사용해 왔다는 것입니다.
대표적인 예가 WAL(Write-Ahead Log, 선행 기록 로그) 파일입니다.
즉, Quack은 새롭게 실험적인 직렬화 방식을 만든 것이 아니라, 이미 충분히 최적화되고 실제 운영 환경에서 검증된(battle-tested) 내부 기술을 재사용한 것입니다.
암호화(Encryption)
DuckDB 팀은 Quack이 설정 없이도 쉽게 동작(“just work”) 하기를 원하지만, 동시에 데이터베이스를 인터넷에 직접 노출했을 때 발생할 수 있는 보안 문제도 매우 신중하게 고려했습니다.
실제로 과거에도 데이터베이스를 인터넷에 직접 연결했다가 문제가 발생한 사례들이 있었습니다.
그래서 Quack은 기본적으로 서버 시작 시 무작위 인증 토큰(Random Authentication Token) 자동 생성, 클라이언트는 이 토큰을 전달받아야 연결 가능, 서버는 기본적으로 localhost에만 바인딩(bind) 되어 외부 접근 차단과 같은 보안 정책을 사용합니다.
또한 Quack은 기본적으로 SSL을 사용하지 않습니다.
그 이유는 로컬 환경(localhost) 통신을 위해 SSL 관련 인프라와 의존성을 모두 추가하는 것이 과하다고 판단했기 때문입니다.
하지만 DuckDB 팀은 Quack 엔드포인트를 인터넷에 직접 공개하는 것을 권장하지 않습니다.
대신 외부 공개가 필요하다면 nginx, SSL 종료(SSL termination), Let's Encrypt를 이용한 HTTPS 구성과 같은 일반적인 HTTP 프록시를 앞단에 두는 방식을 강력히 권장합니다.
Quack 클라이언트는 로컬이 아닌 연결에 대해서는 기본적으로 SSL이 활성화되어 있다고 가정합니다. (필요하면 설정으로 변경 가능)
이를 위한 설정 가이드도 공식 문서에서 제공됩니다.
왕복 횟수(Round-Trips)
DuckDB 팀은 Quack 설계 과정에서 프로토콜 왕복 횟수(round trips), 즉 요청–응답(request/response) 횟수를 최소화하는 데 집중했습니다.
연결이 완료된 이후에는 하나의 쿼리를 단 한 번의 왕복으로 완전히 처리할 수 있습니다.
이 최적화는 특히 지연 시간(latency)에 민감한 환경에서 매우 중요합니다.
동시에 Quack은 대량 응답(Bulk Response) 전송 성능도 강하게 최적화되었습니다.
DuckDB 팀의 설명에 따르면, 현재 Quack은 테이블 데이터를 소켓(socket)으로 전송하는 방식 중 가장 빠른 수준의 구현입니다.
이를 통해 수백만 행(millions of rows) 규모의 데이터도 몇 초 안에 전송할 수 있습니다.
아래에서는 이러한 성능을 보여주는 몇 가지 벤치마크 결과를 소개합니다.
인증(Authentication) 및 권한 부여(Authorization)
데이터베이스 쿼리에 대한 인증과 권한 부여는 끝없는 즐거움과 복잡함의 원천입니다.
우리는 모든 사용 사례를 포괄할 수 없을 가능성이 높습니다. 특히 첫 번째 릴리스에서는 더욱 그렇습니다.
따라서 현명한 선택은 모든 것을 해결하려고 시도하지 않는 것입니다.
Quack에서는 DuckDB의 확장성(extensibility) 철학과 연결되는 인증 모델을 선택했습니다.
이미 수백 개의 DuckDB 확장(extension)이 존재합니다.
Quack은 기본 인증(Authentication) 방식과 권한 제한이 없는 상태로 제공되지만, 둘 다 사용자가 제공하는 코드로 재정의할 수 있습니다.
앞에서 보았듯이 Quack 서버는 시작 시 기본적으로 무작위 인증 토큰(random authentication token) 을 생성합니다.
클라이언트가 연결되면 인증 문자열(authentication string)을 제공합니다.
서버 측에서는 인증 콜백(authentication callback) 을 호출합니다.
기본적으로 이 콜백은 클라이언트가 제공한 토큰과 이전에 무작위로 생성된 토큰을 비교합니다.
하지만 이 콜백은 설정을 통해 변경할 수 있습니다.
예를 들어 사용자는 직접 인증 함수를 만들어 LDAP 디렉터리를 조회하거나, 텍스트 파일을 읽거나, 혹은 그냥 주사위를 굴려 결정할 수도 있습니다.
선택은 전적으로 사용자에게 달려 있습니다.
마찬가지로 권한 부여 함수(authorization function)도 변경할 수 있습니다.
기본 권한 부여 함수는 단순히 모든 요청에 “예(yes)” 라고 응답하지만, 사용자는 클라이언트가 실행하려는 각 쿼리를 검사하고, 해당 쿼리를 이전에 사용된 인증 문자열과 연결하는 등의 작업을 수행할 수 있습니다.
이러한 콜백은 심지어 일반 SQL 매크로(SQL macros) 로도 작성할 수 있습니다.
자세한 내용은 문서를 참고해 주세요.
기본 포트(Default Port)
기본적으로 Quack 서버는 9494 포트에서 요청을 수신(listen)합니다.
숫자 94는 Netscape Navigator가 출시된 해이기 때문에 기억하기 쉽다는 이유로 선택되었습니다.
벤치마크
Quack 프로토콜을 소개하기 위해 두 가지 벤치마크를 구성했습니다. 이 벤치마크는 Arm 환경의 Ubuntu를 실행하는 AWS 가상 머신에서 수행되었습니다. 인스턴스 유형으로는 m8g.2xlarge를 선택했으며, 이 인스턴스는 8개의 vCPU와 32GB RAM을 제공하고, 특히 최대 15Gbps의 네트워크 대역폭을 지원합니다.
실제 환경과 유사한 시나리오를 재현하기 위해 클라이언트와 서버를 동일한 데이터 센터 내에 두되 서로 다른 머신에서 실행했습니다. 또한 두 인스턴스가 동일한 “가용 영역(availability zone)”에 위치하도록 구성했습니다.
두 인스턴스 간의 평균 핑(Ping) 시간은 약 0.280ms였습니다.
대용량 전송(Bulk Transfer)
첫 번째 벤치마크는 대용량 전송을 테스트합니다. 이는 비교적 많은 수의 행(row)을 데이터베이스 프로토콜을 통해 전송해야 하는 상황을 의미합니다. 앞서 링크한 논문을 읽어보셨다면, 전통적인 데이터베이스 프로토콜이 이러한 상황에서 성능 한계를 보여왔다는 점을 알고 계실 것입니다.
이번 비교에서는 Quack과 두 가지 시스템을 비교했습니다. 하나는 널리 사용되는 PostgreSQL 프로토콜이며, 다른 하나는 비교적 최신 프로토콜인 Arrow Flight SQL입니다. Arrow Flight는 내부적으로 DuckDB를 사용하는 GizmoSQL 서버에서 제공됩니다.
벤치마크에서는 TPC-H의 lineitem 테이블에서 점점 더 많은 행을 전송하도록 설정했으며, 최대 6천만 행까지 확장했습니다(이를 CSV 형식으로 저장하면 무려 76GB에 달합니다). 측정값은 총 5회 실행한 결과의 중앙값(median) 기준 실제 소요 시간(wall clock time)을 사용했습니다.
현대적인 대용량 전송 중심 프로토콜이라면 PostgreSQL 프로토콜보다 훨씬 뛰어난 성능을 보여줄 것으로 예상됩니다.
결과는 다음과 같습니다:

Quack은 대용량 결과 집합(result set) 전송에서 매우 뛰어난 성능을 보여줍니다. 6천만 행을 5초 이내에 전송하는 성능을 기록했습니다. 대용량 전송을 위해 설계된 Arrow Flight SQL 프로토콜조차 이 결과와 경쟁하기 어려웠으며, PostgreSQL의 행(Row) 기반 프로토콜은 전반적으로 상당히 불리한 모습을 보였습니다.
공정성을 위해 한 가지 언급할 점이 있습니다. 표준 PostgreSQL 클라이언트는 여러 스레드를 사용한 병렬 읽기(parallel read)를 지원하지 않습니다. 반면 Quack과 Arrow는 이러한 병렬 처리가 가능합니다.
그리고 살짝 홍보를 덧붙이자면(shameless plug), DuckDB의 PostgreSQL 클라이언트도 일부 상황에서는 동일하게 다중 스레드 병렬 읽기를 수행할 수 있습니다.
소규모 쓰기(Small Writes)
두 번째 벤치마크는 작은 단위의 추가(Append) 작업을 테스트합니다. 이는 예를 들어 관측성(observability) 데이터를 하나의 중앙 DuckDB 인스턴스로 수집하는 데 자주 사용되는 시나리오입니다.
이 벤치마크는 데이터베이스 프로토콜에 다른 방식의 부담을 줍니다. 예를 들어 하나의 트랜잭션을 완료하기 위해 클라이언트와 서버 간 여러 번의 왕복(round trip)이 필요하다면 성능상 불리하게 작용합니다.
이를 측정하기 위해 TPC-H의 lineitem 테이블과 동일한 구조를 가진 빈 테이블을 생성한 후, 무작위 값을 삽입했습니다. 각 행(row)은 개별 INSERT 트랜잭션으로 처리되었으며, 삽입되는 값의 분포는 일반적인 벤치마크 생성기의 분포를 어느 정도 따르도록 구성했습니다.
이후 병렬 스레드 수를 점진적으로 늘려가며 5초 동안 테스트를 수행했습니다. 실험은 총 5회 반복했고, 초당 트랜잭션 수(Transactions Per Second, TPS)의 중앙값(median)을 결과로 사용했습니다.
이번 벤치마크에서는 트랜잭션 처리에 최적화된 PostgreSQL이 우수한 성능을 보일 것으로 예상했습니다. 반면 대량 전송에 최적화된 Arrow Flight는 이 시나리오에서 특별히 좋은 성능을 내지 못할 것으로 예상했습니다.

다소 놀랍게도, Quack은 병렬 스레드 8개까지의 구간에서는 PostgreSQL보다 더 높은 성능을 보여주었으며, 초당 약 5,500건의 트랜잭션 처리량에 도달했습니다.
그 이후부터는 현재 DuckDB 자체가 가지고 있는 한계에 도달하게 됩니다. 동일한 테이블에 대해 동시에 수행되는 삽입(concurrent insertion) 처리량이 제한되는 문제입니다.
이 구간에서는 PostgreSQL이 더 좋은 확장성(scale-out 특성)을 보여주었으며, 이는 앞으로 개선이 필요한 영역으로 보고 있습니다.
반면 Arrow Flight는 예상대로 좋은 성능을 보이지 못했습니다. 전체적으로 PostgreSQL 대비 약 절반 수준의 처리 속도를 기록했습니다.
결론
오늘 우리는 DuckDB를 위한 클라이언트-서버 프로토콜인 Quack과, 이를 구현한 초기 버전의 DuckDB 확장을 공개했습니다.
Quack은 DuckDB에 완전한 멀티플레이어 경험(full multiplayer experience)을 제공합니다. 이제 로컬 환경이든 원격 환경이든 여러 개의 독립된 프로세스가 서로를 잠그지(lock) 않고 동시에 테이블의 내용을 수정할 수 있습니다.
이 기능의 일부는 기존에도 DuckLake를 통해 구현할 수 있었지만, Quack은 이를 훨씬 더 단순한 방식으로 제공하며 동시에 훨씬 높은 성능을 제공합니다.
활용 사례(Use Cases)
Quack을 통해 DuckDB는 이제 중앙 집중형 상태 관리(centralized state)가 초저지연의 로컬 쿼리보다 더 중요한 다양한 새로운 활용 사례에서 유용하게 사용될 수 있습니다. 데이터 레이크의 확산과 함께 우리는 이미 데이터가 항상 로컬에 존재하는 것은 아니라는 점을 경험해 왔습니다.
데이터 레이크 이야기가 나온 김에 덧붙이면, Quack은 앞으로 DuckLake에도 통합될 예정입니다. 이를 통해 DuckDB 자체가 원격 접근이 가능한 카탈로그(Catalog) 서버로 동작할 수 있게 됩니다. 이는 예를 들어 데이터 인라이닝(data inlining)과 같은 새로운 기능을 가능하게 할 것입니다. 이에 대해 더 궁금한 점이 있다면 Quack FAQ를 참고해 주세요.
전반적으로 DuckDB는 초기의 “프로세스 내부(in-process)에서 동작하는 인터랙티브 분석용 데이터베이스”라는 위치를 넘어, 현대 데이터 아키텍처의 핵심 구성 요소(core building block)로 점점 확장되고 있습니다.
저희도 한동안 Quack을 직접 사용해 왔고, 여러분이 이를 활용해 어떤 것들을 만들어낼지 매우 기대하고 있습니다. Quack을 더 개선할 수 있는 아이디어가 있다면 꼭 알려주세요.
그리고 마지막으로, MythBusters에서 이미 증명했듯이 오리의 꽥꽥 소리는 메아리친다고 하니(“a duck’s quack echos”), Quack이 앞으로 어떤 반향을 만들어낼지 기대해 봅시다.
다음 단계(Next Steps)
물론 아직 해야 할 일은 많이 남아 있습니다.
우선 Quack을 DuckLake에 통합하여, 원격 DuckDB 서버를 DuckLake의 카탈로그(Catalog)로 사용할 수 있도록 할 예정입니다. 특히 데이터 인라이닝(inlining)과 함께 사용할 경우 성능이 크게 향상될 것으로 기대하고 있습니다.
그다음으로 앞으로 몇 달 동안 Quack을 다듬어 완성도를 높이고, 올해 가을 예정된 DuckDB v2.0과 함께 첫 번째 프로덕션 릴리스를 공개할 계획입니다. 예를 들어 Quack 확장이 필요할 때 자동 설치(auto-installation) 및 자동 로딩(auto-loading)이 가능하도록 지원할 예정입니다.
또한 새롭게 도입된 파서를 기반으로 DuckDB에서 원격 SQL 데이터베이스와 통신하는 구문(syntax)도 더욱 개선할 계획입니다.
DuckDB 코어 측면에서는 초당 처리 가능한 트랜잭션 수(TPS)를 크게 향상시키는 작업도 진행할 예정입니다. 이를 통해 현재의 병렬 스레드 8개 수준을 넘어 훨씬 더 높은 수준의 트랜잭션 확장성을 제공하는 것이 목표입니다.
더 나아가 인증(Authentication)과 권한 부여(Authorization)를 넘어 Quack 프로토콜 자체를 확장할 수 있는 기능도 검토 중입니다. 예를 들어 DuckDB 확장이 새로운 프로토콜 메시지를 추가하고, 이를 처리하는 로직까지 함께 제공할 수 있도록 하는 방향입니다.
또한 Quack 위에 복제(replication) 프로토콜을 추가하는 방안도 고려하고 있습니다. 이를 통해 하나의 DuckDB 인스턴스에서 발생한 변경 사항을 다른 서버로 복제하여, 읽기 전용 복제본(read replica) 클러스터를 구성하는 것도 가능해질 것입니다.
Quack에 대해 더 알아보고 싶거나 초기 도입 사례를 듣고 싶다면, 6월 24일에 열리는 커뮤니티 컨퍼런스 DuckCon #7에 참여해 보세요. DuckCon은 DuckDB 공동 창립자들이 발표하는 “State of the Duck” 세션으로 시작됩니다. 현장 참석뿐 아니라 YouTube 온라인 스트리밍으로도 시청할 수 있습니다.
PS: Quack 프로젝트 전용 페이지도 별도로 준비되어 있으니 꼭 방문해 보세요.
'EPL과 유튜브 데이터로 배우는 DuckDB' 카테고리의 다른 글
| 작은 거인들: 제한된 리소스 환경에서 Postgres, MySQL, ClickHouse, DuckDB 벤치마킹하기 (0) | 2026.05.20 |
|---|---|
| Airflow, DuckDB, Streamlit으로 StarCraft 2 데이터 탐색하기 (0) | 2026.05.20 |
| DuckDB Tricks – Part 3 (0) | 2026.05.18 |
| DuckDB Tricks – Part 2 (0) | 2026.05.17 |
| DuckDB Tricks - Part 1 (0) | 2026.05.17 |




댓글