https://2stndard.tistory.com/notice/203
[발간예정][EPL과 유튜브로 배우는 DuckDB] 실습 코드와 데이터
EPL과 유튜브 데이터로 배우는 DuckDB에서 사용되는 실습 데이터와 코드를 제공합니다. EPL_DATA&samplefile.zip : 책에서 사용하는 영국 프리미어리그 데이터 셋과 샘플로 사용하는 파일espn.duckdb.zip : 책
2stndard.tistory.com
소개 및 개요
이 프로젝트와 이 글은 단순한 지식 공유를 위한 자료가 아니라, 제가 게임을 사랑하는 마음과 데이터가 가진 무한한 가능성을 함께 기념하는 작업이기도 합니다. 이는 두 가지 큰 열정인 게임과 데이터 엔지니어링이 결합된 결과입니다. 저는 어린 시절 StarCraft: Brood War와 StarCraft II를 정말 많이 즐겼습니다. 이 게임은 플레이어가 성간 전쟁 속 세 개의 고유한 종족 중 하나를 선택해 자원 관리, 기지 건설, 전술적 전투를 수행하는 실시간 전략 게임입니다. 비록 최상위 플레이어들이 경쟁하는 그랜드마스터 래더까지 올라가지는 못했지만, 군대를 지휘하고 상대를 압도하며 가끔씩 승리를 거두는 과정에서 느끼는 아드레날린은 매 경기마다 충분히 즐길 수 있었습니다.
예전에는 스타크래프트에서 빌드 오더를 다듬고 상대 전략에 맞춰 대응했다면, 지금은 데이터 엔지니어로서 데이터 파이프라인을 최적화하고, 트렌드를 분석하며, 인사이트를 시각화하고 있습니다. 이번 글에서는 현대 데이터 스택에서 유용하게 활용할 수 있는 세 가지 기술을 소개하고자 합니다.
- Apache Airflow: 복잡한 워크플로를 오케스트레이션하고 예약 실행하기 위한 플랫폼입니다.
- DuckDB: 가볍고 다재다능한 분석용 데이터베이스입니다.
- Streamlit: 인터랙티브 웹 애플리케이션을 쉽게 만들 수 있는 사용자 친화적인 프레임워크입니다.
이 글에서는 각 기술의 기본 개념을 설명하고, 실제 업무 환경에서 어떻게 활용할 수 있는지 예제를 통해 함께 살펴보겠습니다.
마지막으로, 이 모든 요소를 하나로 연결해 StarCraft II 데이터 파이프라인 프로젝트를 만들어보겠습니다. StarCraft II API에서 데이터를 수집하고, Airflow로 이를 오케스트레이션하며, 결과를 DuckDB에 저장합니다. 이후 Streamlit 애플리케이션을 통해 데이터를 시각화하고 현재 StarCraft II 그랜드마스터 래더가 어떤 모습인지 확인해보겠습니다(스포일러: 거기에서 제 이름은 찾을 수 없을 겁니다).
최종 결과물은 다음과 같습니다:
완성된 프로젝트는 Github에서 확인할 수 있습니다 Github 저장소 (sc2-data-pipeline)
그럼 이제 마우스와 키보드를 준비하고, 마음속 프로토스·저그·테란 지휘관을 소환해 보세요. 데이터와 게임이 만나는 흥미로운 세계를 함께 탐험해봅시다.
Airflow
Apache Airflow는 Python을 사용해 워크플로를 프로그래밍 방식으로 작성하고, 스케줄링하며, 모니터링할 수 있도록 해주는 오픈소스 플랫폼입니다. 워크플로는 DAG(Directed Acyclic Graph, 방향성 비순환 그래프) 형태로 표현되며, 그래프의 각 정점(vertex)은 하나의 작업 단위(task)를 의미합니다.
실무에서 이러한 워크플로는 흔히 ETL(Extract, Transform, Load) 프로세스(또는 변환 시점에 따라 ELT)로 구성되는 경우가 많습니다. 하지만 실제로 Airflow는 매우 유연하게 설계되어 있어, 데이터 파이프라인뿐만 아니라 거의 모든 형태의 워크플로를 구현할 수 있습니다.

Airflow는 DAG를 관리하고 모니터링할 수 있는 웹 인터페이스를 제공합니다. Airflow는 크게 네 가지 핵심 구성 요소로 이루어져 있습니다.
- Webserver: Airflow 웹 인터페이스를 제공합니다.
- Scheduler: 설정된 일정에 따라 DAG 실행을 스케줄링합니다.
- Database: DAG와 작업(Task)에 대한 모든 메타데이터를 저장합니다.
- Executor: 개별 작업(Task)을 실제로 실행합니다.
데이터베이스와 실행기(Executor) 측면에서 Airflow는 매우 유연합니다. 예를 들어 SequentialExecutor는 로컬 개발 환경에서 사용할 수 있으며 한 번에 하나의 작업만 실행합니다. 반면 CeleryExecutor나 KubernetesExecutor를 사용하면 여러 워커 노드로 구성된 클러스터 환경에서 작업을 병렬로 실행할 수 있습니다.
이번 프로젝트에서는 Airflow를 사용하여 StarCraft II API에서 데이터를 수집하고 이를 DuckDB에 저장하는 전체 워크플로를 오케스트레이션할 예정입니다.
DuckDB
DuckDB의 세계에 오신 것을 환영합니다! DuckDB를 데이터 분석 세계에서 함께하는 든든한 조력자라고 생각해보세요. 가볍지만 강력한 성능을 갖춘 도구입니다. 스타크래프트 군대에 비유하면, 적진을 민첩하게 돌파하며 정보를 수집하는 정찰 유닛과 같은 존재입니다.
이번 예제 프로젝트에서는 StarCraft II API에서 가져온 데이터, 특히 그랜드마스터 래더 데이터를 저장하기 위해 DuckDB를 사용할 예정입니다. Python을 통해 DuckDB를 임베디드 방식으로 활용하여 하나의 파일 안에 데이터를 저장하는 구조를 구현합니다.
하지만 프로젝트로 바로 들어가기 전에, 다음 장들에서는 DuckDB를 조금 더 자세히 소개하고, 일상적인 데이터 엔지니어링 및 데이터 분석 업무에서 DuckDB를 어떻게 활용하고 어떤 이점을 얻을 수 있는지 살펴보겠습니다.
DuckDB: 휴대 가능한 분석용 데이터베이스
DuckDB를 데이터베이스계의 스위스 아미 나이프라고 생각해보세요. 빠르고 효율적이며 다재다능한 도구입니다. 스타크래프트로 비유하면, 어떤 상황에서도 유연하게 대응할 수 있는 프로토스 질럿(Zealot) 과 같습니다.
DuckDB는 설치가 간단하고, 휴대성이 뛰어나며, 오픈소스입니다. SQL 기능도 매우 풍부하게 제공하며, CSV, Parquet, JSON 등 다양한 데이터 형식을 손쉽게 가져오고 내보낼 수 있습니다.
또한 Pandas 데이터프레임과 자연스럽게 통합되기 때문에, 단순한 분석용 데이터베이스를 넘어 데이터 정제와 가공(Data Wrangling)을 수행하는 스크립트에서도 매우 강력한 도구가 됩니다. 이에 대해서는 다음 장에서 더 자세히 살펴보겠습니다.
Python 프로젝트에서는 다음과 같이 간단하게 설치할 수 있습니다:
pip install duckdb
이후에는 DuckDB를 즉시 사용할 수 있는 인메모리 데이터베이스(in-memory database) 형태로 활용할 수 있습니다:
import duckdb
duckdb.execute("CREATE TABLE tbl AS SELECT 42 a")
df = duckdb.execute("SELECT * FROM tbl").df()
print(df)
a
0 42
또는 임베디드 데이터베이스(embedded database) 로 사용할 수도 있으며, 데이터를 하나의 단일 파일에 영구 저장(persist) 하는 방식으로 활용할 수 있습니다:
import duckdb
# create persisted database and write data
with duckdb.connect(database="my_duckdb.db") as write_conn:
write_conn.execute("CREATE TABLE tbl AS SELECT 42 a")
# somewhere else: read and process data
with duckdb.connect(database="my_duckdb.db", read_only=True) as read_conn:
df = read_conn.execute("SELECT * FROM tbl").df()
print(df)
이렇게 하면 모든 데이터가 my_duckdb.db라는 파일에 저장됩니다. DuckDB와 Pandas 데이터프레임 간에 데이터를 주고받을 수 있을 뿐만 아니라, CSV, JSON 등의 파일도 읽고 쓸 수 있습니다.
SQLite에 익숙하다면, DuckDB를 더 멋지고 성능 중심의 형제 같은 존재라고 생각하면 됩니다. SQLite가 소규모 프로젝트에 적합하다면, DuckDB는 한 단계 더 발전된 성능을 제공합니다. 마치 기본적인 테란 헬리온에서 강력한 토르 유닛으로 업그레이드하는 것과 같아서, 더 큰 데이터셋과 복잡한 쿼리도 땀 한 방울 흘리지 않고 처리할 수 있습니다.
DuckDB는 명령줄 인터페이스(CLI)도 제공합니다. DuckDB CLI는 Windows, Mac, Linux용으로 미리 컴파일된 간단한 실행 파일입니다. Mac 환경에서는 Homebrew를 통해 다음과 같이 간단히 설치할 수 있었습니다:
brew install duckdb
DuckDB의 기능 일부를 보여주기 위해, 이후 프로젝트에서 생성하게 될 DuckDB 데이터베이스 파일에 연결한 뒤 간단한 분석을 수행하는 예제를 사용해 보겠습니다:
SELECT favorite_race, SUM(wins) AS total_wins, MAX(mmr) AS max_mmr, AVG(mmr) AS avg_mmr
FROM ladder
WHERE favorite_race IN ('protoss', 'terran', 'zerg')
GROUP BY favorite_race
ORDER BY total_wins DESC;
┌───────────────┬────────────┬─────────┬───────────────────┐
│ favorite_race │ total_wins │ max_mmr │ avg_mmr │
│ varchar │ int128 │ double │ double │
├───────────────┼────────────┼─────────┼───────────────────┤
│ protoss │ 11816 │ 6840.0 │ 5541.3 │
│ terran │ 7207 │ 7140.0 │ 5501.839285714285 │
│ zerg │ 5380 │ 7080.0 │ 5591.622222222222 │
└───────────────┴────────────┴─────────┴───────────────────┘
- 프로토스(Protoss) 는 그랜드마스터 래더에서 총 승리 수가 가장 많지만, 최고 MMR은 가장 낮았습니다.
- 테란(Terran) 은 그랜드마스터 래더에서 가장 높은 최고 MMR을 기록했습니다.
- 저그(Zerg) 는 총 승리 수는 가장 적었지만, 평균 MMR은 가장 높았습니다.
DuckDB: 다재다능한 데이터 조작 도구
처음 DuckDB를 사용해 프로젝트를 진행하면서 저는 곧 DuckDB가 단순히 가볍고 휴대 가능한 분석용 데이터베이스 이상이라는 점을 깨달았습니다. 실제로 DuckDB는 데이터 가공(Data Wrangling)을 위한 도구 상자에 추가하면 매우 강력한 도구가 될 수 있습니다.
DuckDB의 핵심 강점 중 하나는 SQL 기반 작업과 Pandas 같은 데이터 처리 도구 사이를 자연스럽게 연결해준다는 점입니다. 이 독특한 특징 덕분에 데이터 처리 스크립트 안에서 여러 기술을 부담 없이 오가며 사용할 수 있습니다.
기존처럼 데이터 가공을 전부 SQL로 구현하거나, Pandas·NumPy 같은 Python 라이브러리만 사용해서 처리할 필요가 없습니다. 복잡한 데이터베이스 연동 환경을 구축하지 않아도 상황에 따라 SQL과 Python 환경을 자유롭게 전환할 수 있습니다.
예를 들어 API에서 데이터를 가져온 뒤 Pandas 데이터프레임으로 로드하고, 이를 인메모리 DuckDB에 넣어 SQL로 집계를 수행한 다음, 결과를 다시 데이터프레임으로 가져와 후속 처리를 계속할 수 있습니다. 오버헤드도 크지 않습니다. 특히 SQL을 자주 사용하는 데이터 엔지니어 입장에서는 더 직관적인 데이터 흐름을 설계할 수 있는 강력한 도구가 됩니다.
이것은 스타크래프트에서 상황에 맞는 유닛 조합을 선택하는 것과 비슷합니다. 질럿만 계속 생산할 수도 있지만, 상대가 다수의 바퀴(Roach)로 공격해온다면 조합을 조정해서 이모탈(Immortal)나 공허 포격기(Void Ray)를 추가해야 합니다. 데이터 가공 스크립트도 마찬가지입니다. DuckDB 같은 도구를 전체 구성에 포함하면 데이터 처리 과정에서 훨씬 다양한 문제에 대응할 수 있게 됩니다.
다음 예제에서는 Airflow DAG를 통해 수집한 StarCraft II 래더 데이터를 읽어와 SQL로 집계를 수행하고, 결과를 Pandas 데이터프레임으로 변환합니다. 이후 Pandas를 이용해 일부 컬럼을 추가하고, 다시 인메모리 DuckDB 테이블로 되돌려 추가 변환을 수행한 뒤, 최종 결과를 다시 Pandas 데이터프레임으로 가져오는 과정을 살펴보겠습니다.
import duckdb
if __name__ == '__main__':
# use persisted duckdb
with duckdb.connect(database="sc2data.db") as conn:
df = conn.sql(f"""
SELECT
favorite_race,
SUM(wins) AS total_wins,
SUM(losses) AS total_losses,
MAX(mmr) AS max_mmr,
AVG(mmr) AS avg_mmr
FROM ladder
WHERE favorite_race IN ('protoss', 'terran', 'zerg')
GROUP BY favorite_race
ORDER BY total_wins DESC;
""").df()
print(df)
# data wrangling in pandas
df["win_pct"] = (df["total_wins"] / (df["total_wins"] + df["total_losses"]) * 100)
# use in-memory duckdb for further processing
duckdb.sql("""
CREATE TABLE aggregation AS
SELECT CASE
WHEN favorite_race = 'protoss' THEN 'p'
WHEN favorite_race = 'terran' THEN 't'
WHEN favorite_race = 'zerg' THEN 'z'
END AS fav_rc,
total_wins + total_losses AS total_games,
win_pct
FROM df;
""")
# back to pandas
df_agg = duckdb.sql("SELECT * FROM aggregation;").df()
print(df_agg)위 코드와 StarCraft II API의 그랜드마스터 래더 데이터를 사용하면 다음과 같은 출력이 생성됩니다:
favorite_race total_wins total_losses max_mmr avg_mmr
0 protoss 7024.0 5921.0 6861 4940.141026
1 terran 6927.0 5899.0 5921 4853.368421
2 zerg 4997.0 4140.0 5699 4820.431373
fav_rc total_games win_pct
0 p 12945.0 54.260332
1 t 12826.0 54.007485
2 z 9137.0 54.689723
이를 통해 우리는 프로토스가 그랜드마스터 래더에서 가장 많이 선택되는 종족이라는 점뿐만 아니라, DuckDB와 Pandas의 뛰어난 호환성이 데이터 과학자와 분석가에게 얼마나 다양한 가능성을 제공하는지도 확인할 수 있습니다.
DuckDB의 SQL 처리 능력과 Pandas의 데이터 조작 기능을 자연스럽게 오가며 사용할 수 있기 때문에, 사용자는 각 플랫폼의 장점을 동시에 활용할 수 있습니다. 이를 통해 데이터 처리 워크플로의 효율성과 유연성을 극대화할 수 있습니다.
결국 DuckDB는 전통적인 데이터베이스의 경계를 넘어, 다양한 기술과 자연스럽게 통합되어 데이터 처리를 간소화하는 다목적 도구로 진화한 플랫폼이라고 할 수 있습니다.
숫자를 집계하든, 데이터셋을 변환하든, 복잡한 분석을 수행하든 관계없이 DuckDB는 믿을 수 있는 동반자 역할을 합니다. SQL의 편리함과 함께 Pandas 및 다양한 라이브러리의 유연성을 결합하여, 효율적인 데이터 조작과 분석 환경을 제공합니다.
Streamlit
Streamlit은 데이터를 시각화하고 상호작용할 수 있는 웹 애플리케이션을 손쉽게 만들 수 있도록 지원하는 오픈소스 앱 프레임워크입니다. 이렇게 만든 앱은 로컬 환경에서 실행할 수도 있고, 무료로 제공되는 Streamlit Community Cloud에 배포하여 공유할 수도 있습니다.
Streamlit은 기본적으로 다양한 형태의 데이터를 표현할 수 있는 풍부한 UI 요소들을 제공합니다. 여기에 더해, 기능을 확장할 수 있는 수많은 서드파티 모듈(컴포넌트, Components) 도 존재하여 더욱 다양한 인터랙티브 기능과 시각화를 구현할 수 있습니다.
Python 프로젝트에서는 다음과 같이 간단하게 설치할 수 있습니다:
pip install streamlit
그다음 전용 스크립트 파일에서 앱을 작성한 후, streamlit run 명령어를 사용하여 실행할 수 있습니다:
streamlit run your_script.py [-- script args]
Python 스크립트를 위에서 아래로 순차적으로 구성되는 앱의 코드 표현이라고 생각해보세요. 다음과 같이 작성하면:
import streamlit as st
st.title("My Streamlit App")
간단한 헤더가 포함된 웹 앱을 얻을 수 있습니다.

Airflow, DuckDB, Streamlit으로 StarCraft II 데이터 파이프라인 만들기
이 프로젝트의 기본 아이디어는 다음과 같습니다. 먼저 StarCraft II API에서 데이터를 가져옵니다. 더 정확히 말하면, 현재 이 게임에서 최고 중의 최고가 누구인지 확인하기 위해 이른바 그랜드마스터 래더(grandmaster ladder) 정보를 가져올 것입니다.
그다음 해당 데이터를 DuckDB 파일에 저장하고, 이 과정을 TaskFlow API를 사용하는 Airflow DAG로 오케스트레이션합니다. 마지막으로 Streamlit을 사용해 간단한 앱을 만들겠습니다.
최종 프로젝트는 Github에서도 확인할 수 있습니다 🪄:
https://github.com/vojay-dev/sc2-data-pipeline
하지만 이어지는 장에서는 이 StarCraft II 데이터 파이프라인을 단계별로 구현하는 방법을 설명하겠습니다.
이 프로젝트를 실행한 환경은 다음과 같습니다.
OS: macOS Sonoma
Python: 3.11.8
(필자가 실행한 환경은 Windows 11에 Python 3.14 입니다.)
프로젝트 설정
(여기서부터는 필자의 프로젝트 환경을 사용합니다. 출처 블로그의 환경과 차이가 있을 수 있습니다. )
먼저 새로운 Python 프로젝트를 생성하는 것부터 시작합니다. 이를 위해 새로운 폴더를 만들고, 해당 폴더 안에서 Python의 내장 모듈인 venv를 사용해 가상 환경(virtual environment)을 생성합니다:
mkdir battle.net
cd battle.net
python -m venv battlenet
cd battlenet/Scripts
activate

마지막 명령을 실행하면 가상 환경도 함께 활성화됩니다. 즉, 해당 터미널 세션에서 실행하는 모든 작업은 시스템 전체에 설치된 Python이 아니라 가상 환경의 Python을 사용하게 됩니다.
이 과정은 매우 중요합니다. 이후 설치할 의존성들이 시스템 환경과 섞이지 않고 프로젝트 내부에 독립적으로 유지되도록 하기 때문입니다.
이번 프로젝트에서는 Airflow, DuckDB, Streamlit, Pandas, PyArrow를 사용하므로, 다음 단계로 필요한 패키지들을 모두 설치합니다:
# Install Airflow
AIRFLOW_VERSION=2.8.2
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)"
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
# Install DuckDB
pip install duckdb
# Install Pandas and PyArrow
pip install pandas
pip install pyarrow
# Install Streamlit
pip install streamlit
(블로그는 Mac 환경인듯 합니다. 저는 윈도우 환경이라 Airflow는 도커로 다음과 같이 설치하였습니다. 다음은 윈도우즈 파워쉘에서의 실행코드입니다.)
# 폴더 생성 및 이동 (원하는 다른 경로가 있다면 수정 가능)
mkdir D:\tistory\duckdb\battle.net\airflow-docker
cd D:\tistory\duckdb\battle.net\airflow-docker
curl -Uri 'https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml' -OutFile 'docker-compose.yaml'
mkdir dags, logs, plugins, config
# UTF-8 인코딩으로 Airflow UID 설정 생성
[System.IO.File]::WriteAllText("$PWD\.env", "AIRFLOW_UID=50000`n", [System.Text.Encoding]::UTF8)
# 컨테이너 구동 시 DuckDB가 자동으로 설치되도록 요구사항 추가
[System.IO.File]::AppendAllText("$PWD\.env", "_PIP_ADDITIONAL_REQUIREMENTS=duckdb`n", [System.Text.Encoding]::UTF8)
# 메타데이터 초기화 (딱 한 번만 실행, 마지막에 exited with code 0이 나오면 성공)
docker compose up airflow-init
# Airflow 서비스를 백그라운드로 진짜 실행
docker compose up -d
보시다시피 이번 프로젝트에서는 Airflow 2.8.2를 사용합니다.(저는 3.2.1을 사용합니다.)
또한 왜 Poetry나 최소한 requirements.txt를 사용하지 않고 의존성을 직접 설치하는지 궁금할 수 있습니다. Airflow는 로컬 환경에서 직접 설치하는 방식이 가장 안정적으로 동작하는 경우가 많으며, 현재 공식적인 Poetry 지원도 제공되지 않습니다.
이러한 이유와 함께 프로젝트 구성을 최대한 단순하게 유지하기 위해, 이번 예제에서는 패키지를 수동으로 설치하는 방식을 선택합니다.
Airflow 준비하기
(저는 도커를 사용하기 때문에 이 부분은 건너뛰었습니다.)
Airflow는 설정 파일과 같은 일부 데이터를 관리하기 위해 로컬 디스크에 airflow라는 폴더를 사용합니다. 일반적으로 이 폴더는 현재 사용자 홈 디렉터리에 생성됩니다. 하지만 다른 프로젝트와의 충돌을 피하기 위해, 이번에는 AIRFLOW_HOME 환경 변수를 설정하여 프로젝트 폴더를 기준으로 Airflow 폴더를 생성하겠습니다.
Airflow를 처음으로 standalone 모드에서 시작하면, 지정한 위치에 기본 설정이 포함된 폴더가 생성됩니다. 이때 Airflow는 SequentialExecutor를 사용하고, 데이터베이스로는 SQLite를 사용하며, 데이터베이스 파일은 AIRFLOW_HOME 위치에 저장됩니다.
다음 명령은 AIRFLOW_HOME 환경 변수를 현재 디렉터리, 즉 프로젝트 디렉터리 안의 airflow 폴더로 설정한 뒤, Airflow를 standalone 모드로 시작합니다. 또한 명령에 NO_PROXY라는 또 다른 환경 변수도 추가합니다. 이는 macOS에서 알려진 이슈 때문인데, Airflow 웹 인터페이스를 통해 DAG를 실행할 때 SIGSEGV가 발생할 수 있기 때문입니다.
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" airflow standalone이렇게 하면 Airflow가 시작될 뿐만 아니라 프로젝트 디렉터리에 airflow 폴더가 생성됩니다. 또한 웹 인터페이스용 관리자 계정이 자동으로 생성됩니다. 로그 출력에서 사용자 이름과 비밀번호를 확인할 수 있습니다.

standalone | Airflow is ready
standalone | Login with username: admin password: FZCvvSd8WVYDb2Vm
standalone | Airflow Standalone is for development purposes only. Do not use this in production!
(도커는 airflow/airflow입니다)
이제 브라우저에서 http://localhost:8080/을 열고, 로그 출력에 표시된 인증 정보를 사용해 로그인할 수 있습니다.

이제 실용적인 로컬 Airflow 환경이 준비되었습니다. 웹 인터페이스에 표시되는 경고는 standalone 모드에서 자동으로 SequentialExecutor와 SQLite 데이터베이스를 사용하기 때문에 나타나는 것입니다. 따라서 이 구성은 당연히 운영(Production) 환경용이 아니라 개발 및 실험용입니다.
standalone 프로세스는 control + c로 종료할 수 있습니다.
이제 DAG 작업을 시작하기 전에 환경을 조금 더 정리해보겠습니다.
한 가지 눈치챘을 수도 있는데, 기본적으로 여러 개의 예제 DAG(example DAG) 가 표시됩니다. 개인적으로는 처음 시작할 때 더 깔끔한 환경을 선호합니다. 이러한 예제 DAG들은 특정 설정 값이 활성화되어 있을 때 Airflow 시작 시 자동으로 생성됩니다. 따라서 먼저 이 설정을 변경해보겠습니다.
앞에서 AIRFLOW_HOME 환경 변수를 프로젝트 내부의 airflow 폴더로 지정했기 때문에, 설정 파일의 위치는 다음과 같습니다.
airflow/airflow.cfg
사용하는 편집기로 설정 파일을 열고, 다음 설정을 변경하십시오:
load_examples = False
지금 독립 실행형 프로세스를 다시 시작하더라도, 예제 DAG는 데이터베이스에 저장되어 있으므로 여전히 표시될 수 있습니다. 따라서 다음 명령어를 사용하여 데이터베이스도 함께 초기화해야 합니다(먼저 가상 환경을 활성화하고 프로젝트 폴더로 이동해 두십시오).
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" airflow db reset
‘y’를 입력하여 확인한 후 환경을 다시 시작하면, 이제 환경이 초기화된 상태가 됩니다. 이렇게 하면 새로운 관리자 사용자가 생성되지만, 이번에는 예제 DAG는 생성되지 않습니다.
NO_PROXY="*" AIRFLOW_HOME="$(pwd)/airflow" airflow standalone

DAG를 만들기 전에 한 가지 더 조정해야 할 부분이 있습니다. 일반적으로 프로젝트를 Git 저장소에 커밋할 때는 airflow 폴더 전체를 저장소에 포함하지 않는 것이 일반적입니다. 그 이유는 두 가지입니다. 첫째, 운영 환경에서는 보통 이 폴더가 프로젝트 내부에 위치하지 않습니다. 둘째, 현재 구성은 로컬 개발 환경용이므로 다른 개발자들도 각자 환경을 독립적으로 구성할 수 있도록 해야 합니다.
따라서 일반적으로는 .gitignore 파일에 다음 항목을 추가하게 됩니다.
airflow/
하지만 여기에는 문제가 있습니다. Airflow는 기본적으로 DAG를 airflow 폴더 내부의 dags 폴더, 즉 airflow/dags 에서 찾습니다. 만약 DAG 구현 코드를 여기에 두면서 동시에 .gitignore에서 airflow/를 제외하면, 별도 우회 방법 없이 DAG 코드를 저장소에 커밋할 수 없게 됩니다.
다행히 해결 방법은 간단합니다. Airflow 설정에서 DAG 폴더 위치를 변경하면 됩니다.
이를 위해 DAG 저장 위치를 프로젝트 루트 내부의 dags 폴더로 변경하겠습니다.
설정을 변경하려면 다시 airflow/airflow.cfg 파일을 열고 dags_folder 설정 항목을 찾습니다. 그리고 다음과 같이 프로젝트 폴더 안의 dags 디렉터리를 가리키도록 수정합니다.
예:
dags_folder = /tmp/sc2-data-pipeline/dags
마지막으로 프로젝트 내에 빈 dags 폴더를 생성하면 모든 준비가 완료됩니다.
mkdir dagsStarCraft II API 접근 권한 얻기
이번에 사용할 API는 StarCraft II Community API의 일부입니다.
요청 제한도 상당히 여유로운 편입니다. 시간당 36,000회 요청, 초당 100회 요청까지 허용되므로, 이번 시나리오에서는 DAG를 원하는 만큼 자주 실행해도 충분합니다.
API 접근 권한을 얻으려면 OAuth 클라이언트를 생성해야 하며, 이는 battle.net 계정만 있으면 무료로 생성할 수 있습니다.
먼저 아래 페이지로 이동합니다.
Battle.net Developer Portal - OAuth Clients
그다음 battle.net 계정으로 로그인한 후 새로운 클라이언트를 생성하면 됩니다.

이 과정을 통해 다음 두 가지 정보를 얻게 됩니다.
a client ID and
a client secret.
둘 다 API에 접근하는 데 필요하므로 안전하게 보관해야 합니다.
기본 흐름은 먼저 client ID와 client secret을 사용해 access token을 발급받고, 이후 이 토큰을 사용해 Community API에서 데이터를 가져오는 방식입니다.
다음 예제는 터미널에서 curl과 jq를 사용하여 이를 수행하는 방법을 보여줍니다. jq는 `brew install jq` 명령어로 설치할 수 있습니다.
curl -s -u your_client_id:your_client_secret -d grant_type=client_credentials https://oauth.battle.net/token | jq .
윈도우의 경우
curl.exe -u your_client_id:your_client_secret -d grant_type=client_credentials https://oauth.battle.net/token | jq .DAG 구현
dags 폴더에 sc2.py라는 Python 파일을 생성합니다. 이 파일이 바로 우리의 DAG 구현체가 될 것입니다. 다음 코드를 추가하세요. 이 코드는 기본적으로 TaskFlow API를 사용한 DAG 구현입니다. 자세한 내용은 나중에 살펴보겠습니다:
import logging
import pendulum
import requests
from airflow.decorators import dag, task, task_group
from airflow.models import Variable
from requests.adapters import HTTPAdapter
from urllib3 import Retry
import duckdb
import pandas as pd
logger = logging.getLogger(__name__)
DUCK_DB = "/opt/airflow/dags/sc2data.db"
CLIENT_ID = "your client ID"
CLIENT_SECRET = "your client secret"
BASE_URI = "https://kr.api.blizzard.com"
REGION_ID = 3 # Asia (Korea/Taiwan)
# retry strategy for contacting the StarCraft 2 API
MAX_RETRIES = 4
BACKOFF_FACTOR = 2
@dag(start_date=pendulum.now())
def sc2():
retry_strategy = Retry(total=MAX_RETRIES, backoff_factor=BACKOFF_FACTOR)
adapter = HTTPAdapter(max_retries=retry_strategy)
session = requests.Session()
session.mount('https://', adapter)
@task
def get_access_token() -> str:
data = {"grant_type": "client_credentials"}
response = session.post("https://oauth.battle.net/token", data=data, auth=(CLIENT_ID, CLIENT_SECRET))
return response.json()["access_token"]
@task
def get_grandmaster_ladder_data(token: str):
headers = {"Authorization": f"Bearer {token}"}
response = session.get(f"{BASE_URI}/sc2/ladder/grandmaster/{REGION_ID}", headers=headers)
ladder_teams = response.json().get("ladderTeams", [])
return [{
"id": lt["teamMembers"][0]["id"],
"realm": lt["teamMembers"][0]["realm"],
"region": lt["teamMembers"][0]["region"],
"display_name": lt["teamMembers"][0]["displayName"],
"clan_tag": lt["teamMembers"][0]["clanTag"] if "clanTag" in lt["teamMembers"][0] else None,
"favorite_race": lt["teamMembers"][0]["favoriteRace"] if "favoriteRace" in lt["teamMembers"][0] else None,
"previous_rank": lt["previousRank"],
"points": lt["points"],
"wins": lt["wins"],
"losses": lt["losses"],
"mmr": lt["mmr"] if "mmr" in lt else None,
"join_timestamp": lt["joinTimestamp"]
} for lt in ladder_teams if lt["teamMembers"] and len(lt["teamMembers"]) == 1]
def get_profile_metadata(token: str, region: str, realm: int, player_id: int) -> dict:
headers = {"Authorization": f"Bearer {token}"}
response = session.get(f"{BASE_URI}/sc2/metadata/profile/{region}/{realm}/{player_id}", headers=headers)
return response.json() if response.status_code == 200 else None
@task
def enrich_data(token: str, data: list) -> list:
logger.info("Fetching metadata for %d players", len(data))
for i, player in enumerate(data, start=1):
logger.info("Fetching metadata for player %d/%d", i, len(data))
metadata = get_profile_metadata(token, player["region"], player["realm"], player["id"])
player["profile_url"] = metadata.get("profileUrl") if metadata else None
player["avatar_url"] = metadata.get("avatarUrl") if metadata else None
player["name"] = metadata.get("name") if metadata else None
print(data)
return data
@task
def create_pandas_df(data: list) -> pd.DataFrame:
return pd.DataFrame(data)
@task
def store_data_in_duckdb(ladder_df: pd.DataFrame) -> None:
with duckdb.connect(DUCK_DB) as conn:
conn.sql(f"""
DROP TABLE IF EXISTS ladder;
CREATE TABLE ladder AS
SELECT * FROM ladder_df;
""")
@task_group
def get_data() -> list:
access_token = get_access_token()
ladder_data = get_grandmaster_ladder_data(access_token)
return enrich_data(access_token, ladder_data)
@task_group
def store_data(enriched_data: list) -> None:
df = create_pandas_df(enriched_data)
store_data_in_duckdb(df)
store_data(get_data())
sc2()
DAG의 기본 흐름은 꽤 간단한데, 서로 연결된 두 가지 주요 작업 그룹, 즉 get_data와 store_data로 구성되어 있습니다.

이제 이러한 태스크 그룹의 주요 요소 몇 가지를 살펴보겠습니다.
데이터 가져오기
데이터 수집은 다음 3단계로 이루어지며, 각 단계는 Airflow에서 하나의 작업(Task)으로 실행됩니다.
- get_access_token: client ID와 secret을 사용해 새로운 access token을 가져옵니다.
- get_grandmaster_ladder_data: 발급받은 토큰을 사용해 모든 플레이어가 포함된 최신 그랜드마스터 래더 데이터를 가져옵니다.
- enrich_data: 다른 API 엔드포인트를 사용해 래더의 각 항목에 플레이어의 프로필 URL, 아바타, 이름 정보를 추가합니다.
requests.get이나 requests.post 함수를 직접 사용하는 대신, 모든 요청에 사용할 session을 생성합니다. 이렇게 하면 retry 전략과 backoff 전략도 함께 정의할 수 있습니다. 외부 API 소스에서 데이터를 가져올 때는 이런 방식이 권장됩니다. API가 일시적으로 사용할 수 없다는 이유만으로 DAG가 실패하도록 두고 싶지는 않기 때문입니다.
MAX_RETRIES = 4
BACKOFF_FACTOR = 2
retry_strategy = Retry(total=MAX_RETRIES, backoff_factor=BACKOFF_FACTOR)
adapter = HTTPAdapter(max_retries=retry_strategy)
session = requests.Session()
session.mount('https://', adapter)
이를 통해 작업 내에서 세션을 사용하여 요청을 보낼 수 있습니다. 예를 들어, 액세스 토큰을 가져오는 경우처럼 말이죠:
@task
def get_access_token() -> str:
data = {"grant_type": "client_credentials"}
response = session.post("https://oauth.battle.net/token", data=data, auth=(CLIENT_ID, CLIENT_SECRET))
return response.json()["access_token"]
get_grandmaster_ladder_data 작업에서는 https://eu.api.blizzard.com/sc2/ladder/grandmaster/{REGION_ID} 엔드포인트를 호출하여 최신 그랜드마스터 래더 데이터를 가져옵니다. 여기서 REGION_ID는 이번 프로젝트에서 3으로 설정되어 있으며, 아시아&한국(Asia) 지역 데이터를 조회하기 위한 값입니다.
마지막으로 enrich_data 작업에서는 래더에 포함된 각 플레이어에 대해 https://eu.api.blizzard.com/sc2/metadata/profile/{region}/{realm}/{player_id} 엔드포인트를 호출하여 추가 정보를 가져옵니다. 이렇게 가져온 정보를 기존 플레이어 데이터에 결합하여 보강(enrich)합니다.
실제 프로필 메타데이터를 조회하는 API 호출 로직은 get_profile_metadata 헬퍼 함수 내부에 캡슐화되어 있습니다.
데이터 저장하기
데이터 저장은 다음 2단계로 이루어지며, 각 단계는 Airflow에서 하나의 작업(Task)으로 실행됩니다.
- create_pandas_df: 플레이어 목록을 기반으로 Pandas 데이터프레임을 생성합니다.
- store_data_in_duckdb: 생성한 데이터프레임을 파일에 영구 저장되는 DuckDB에 저장합니다.
앞서 설명했듯이 DuckDB는 다양한 데이터 형식을 읽고 쓸 수 있으며, Pandas 데이터프레임도 직접 지원합니다. 따라서 첫 번째 단계에서는 딕셔너리 리스트를 데이터프레임으로 변환합니다. 여기서 각 딕셔너리는 래더에 포함된 한 명의 플레이어 정보를 나타냅니다.
@task
def create_pandas_df(data: list) -> pd.DataFrame:
return pd.DataFrame(data)
이 데이터프레임을 DuckDB에 저장하는 것은 놀라울 정도로 간단합니다. 코드를 처음 보면 놀라실 수도 있겠지만, 맞습니다. SQL에서 데이터프레임 변수를 직접 참조할 수 있습니다:
@task
def store_data_in_duckdb(ladder_df: pd.DataFrame) -> None:
with duckdb.connect(DUCK_DB) as conn:
conn.sql(f"""
DROP TABLE IF EXISTS ladder;
CREATE TABLE ladder AS
SELECT * FROM ladder_df;
""")
데이터를 파일에 영구 저장하는 방식이기 때문에, 이번 프로젝트에서는 매 실행마다 기존 데이터를 삭제한 뒤 최신 데이터만 저장하도록 구현합니다. 물론 INSERT OR REPLACE를 사용할 수도 있습니다. 하지만 그렇게 하려면 기본 키(primary key) 제약 조건을 정의해야 하는데, 데이터프레임을 기반으로 테이블을 직접 생성하는 방식에서는 이를 설정하기가 쉽지 않습니다.
하지만 이번 사용 사례에서는 현재 방식으로도 충분합니다. 이런 상황에서 저는 종종 KISS 원칙을 떠올립니다.
KISS (Keep It Simple, Stupid)
즉, 불필요하게 복잡하게 만들지 말고 가능한 한 단순하게 유지하라는 원칙입니다.
Streamlit으로 데이터 시각화하기
Streamlit 앱을 만들기 위해 프로젝트 루트 디렉터리에 새로운 파일 app.py 를 생성합니다. 그리고 다음 내용을 추가하면 됩니다:
import streamlit as st
st.title("StarCraft 2 Grandmaster Ladder")
그리고 다음을 통해 앱을 실행하세요
streamlit run app.py
헤더가 포함된 간단한 웹 페이지가 표시됩니다. 앱을 확장하면 페이지가 자동으로 새로 고쳐집니다. 이제 DuckDB에서 데이터를 읽어와 화면에 표시하는 실제 앱으로 이 내용을 대체해 보겠습니다:
import streamlit as st
import duckdb
con = duckdb.connect(database="D:/tistory/DuckDB/battle.net/airflow-docker/dags/sc2data.db", read_only=True)
st.title("StarCraft 2 Grandmaster Ladder")
@st.cache_data
def load_ladder_data():
df = con.execute("SELECT * FROM LADDER").df()
# sort by mmr and move avatar to first column
df.sort_values("mmr")
avatar_url = df.pop("avatar_url")
df.insert(0, "avatar", avatar_url)
return df
@st.cache_data
def load_favorite_race_distribution_data():
df = con.execute("""
SELECT favorite_race, COUNT(*) AS count
FROM LADDER
WHERE favorite_race IS NOT NULL
GROUP BY 1
ORDER BY 2 DESC
""").df()
return df
ladder = load_ladder_data()
st.dataframe(ladder, column_config={
"avatar": st.column_config.ImageColumn("avatar")
})
distribution_data = load_favorite_race_distribution_data()
st.bar_chart(distribution_data, x="favorite_race", y="count")
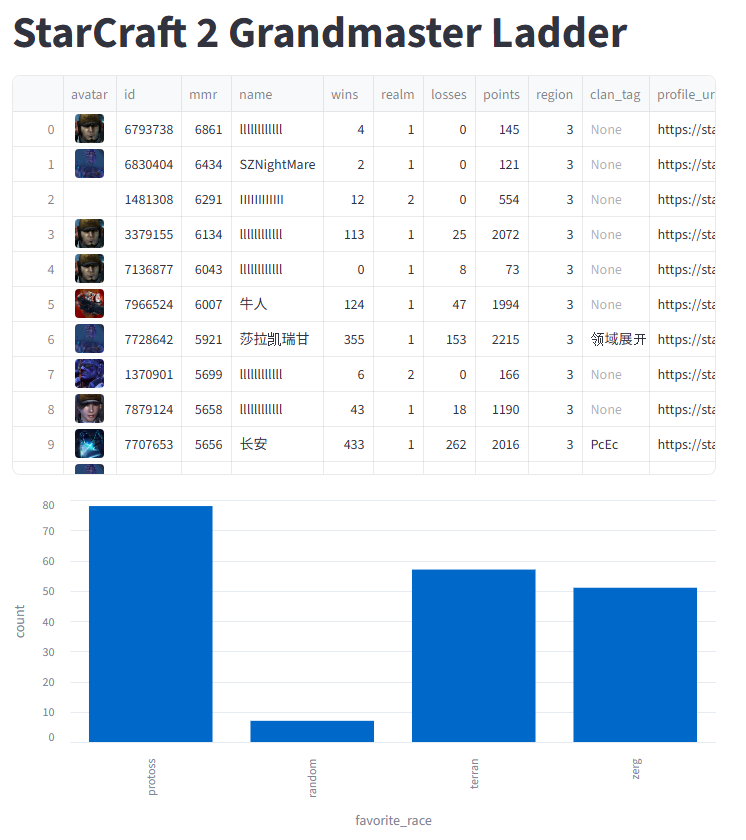
이를 통해 마침내 스타크래프트 II 그랜드마스터 랭킹 데이터를 MMR 순으로 시각화할 수 있으며, 플레이어의 아바타까지 확인할 수 있습니다:
이 앱 구현은 Pandas 데이터프레임과 DuckDB를 결합하여 강력한 데이터 가공(Data Wrangling) 도구로 활용하는 좋은 예시를 다시 한번 보여줍니다.
df = con.execute("SELECT * FROM LADDER").df()
# sort by mmr and move avatar to first column
df.sort_values("mmr")
avatar_url = df.pop("avatar_url")
df.insert(0, "avatar", avatar_url)
return df
Streamlit에서는 데이터프레임을 매우 쉽게 렌더링할 수 있을 뿐만 아니라, 특정 컬럼의 표시 방식을 변경하여 앱에서 원하는 형태로 표현할 수도 있습니다.
이번 예제에서는 avatar 컬럼에 저장된 URL 값을 가져와 실제 이미지로 렌더링하도록 구성합니다. 이렇게 하면 단순히 텍스트 형태의 링크를 보여주는 것이 아니라, 플레이어의 아바타를 앱 화면에서 바로 시각적으로 확인할 수 있습니다.
st.dataframe(ladder, column_config={
"avatar": st.column_config.ImageColumn("avatar")
})
결론적으로, 그랜드마스터 랭킹에서는 프로토스가 가장 두각을 나타내는 진영인 것으로 보입니다. 저 역시 예전에 프로토스 유저였기에 참 반가운 일이네요.
결론
결론적으로, Apache Airflow, Streamlit, 그리고 DuckDB를 활용해 데이터 파이프라인을 구축한 이번 여정은 데이터 파이프라인 오케스트레이션과 인터랙티브 데이터 애플리케이션 개발에 대한 매우 유익한 기술적 인사이트를 제공했습니다.
DuckDB는 데이터 가공(Data Wrangling) 과정에서 강력한 동반자로 자리 잡았습니다. Pandas 데이터프레임과의 자연스러운 통합, 그리고 강력한 분석용 SQL 기능을 제공하며 큰 장점을 보여주었습니다. 또한 가볍고 효율적인 특성 덕분에 제한된 자원 환경에서도 분석 워크로드에 적합한 선택지임을 확인할 수 있었습니다.
Streamlit은 직관적인 인터페이스와 뛰어난 시각화 기능을 통해 인터랙티브 데이터 애플리케이션을 빠르게 개발할 수 있는 가능성을 보여주었습니다.
이번에 살펴본 기술들을 되돌아보면, 이들이 현대적인 데이터 엔지니어링 및 데이터 분석 워크플로에서 얼마나 중요한 역할을 하는지 다시금 확인할 수 있습니다. 스타크래프트 II의 그랜드마스터 플레이어가 유닛 조합을 신중하게 설계하듯, 여러분도 데이터 엔지니어링 도구 상자를 꾸준히 확장하고 최적화해 보세요.
다음 데이터 탐험의 여정까지, 여러분의 파이프라인이 항상 안정적으로 흐르고, 여러분의 성과가 완벽한 타이밍의 래버저(Ravager) 포격만큼 짜릿하길 바랍니다.
'EPL과 유튜브 데이터로 배우는 DuckDB' 카테고리의 다른 글
| 데이터 엔지니어를 위한 DuckDB (0) | 2026.05.22 |
|---|---|
| 작은 거인들: 제한된 리소스 환경에서 Postgres, MySQL, ClickHouse, DuckDB 벤치마킹하기 (0) | 2026.05.20 |
| Quack: DuckDB의 클라이언트-서버 프로토콜 (0) | 2026.05.19 |
| DuckDB Tricks – Part 3 (0) | 2026.05.18 |
| DuckDB Tricks – Part 2 (0) | 2026.05.17 |




댓글