데이터 과학 수업에서는 거의 항상 이런 장면이 펼쳐집니다. 한 학생이 숫자로 가득한 표를 바라보다가 칠판을 올려다보며 묻습니다.
“그런데 이게 실제로 무슨 의미가 있죠?”
좋은 질문입니다. 왜냐하면 원시 데이터(raw data)는 그 자체로는 단지 잡음(noise)에 불과하기 때문입니다. 통계학은 그 잡음을 신호(signal)로 바꾸는 기술이며, 그 중심에는 두 개의 거대한 축이 있습니다. 바로 기술통계(Descriptive Statistics)와 추론통계(Inferential Statistics)입니다.
이 둘은 단순히 교과서의 한 챕터가 아닙니다. 머신러닝 엔지니어, 역학 연구자, 프로덕트 매니저, 그리고 과학자들이 세상을 이해하는 방식 자체를 구성하는 렌즈입니다. 이 개념들을 깊이 이해하게 되면, 이전에는 보이지 않던 패턴들이 곳곳에서 보이기 시작할 것입니다.
그럼 이제 함께 그 여정을 시작해봅시다.
피자 가게 비유: 첫 번째 통계 수업
코드를 다루기 전에, 먼저 사람의 이야기로 생각해봅시다.
당신이 피자 가게를 운영한다고 상상해보세요. 어느 토요일 밤, 200명의 고객에게 피자를 제공했습니다. 그리고 각 고객이 피자를 받기까지 기다린 시간을 기록해 두었습니다.
기술통계(Descriptive Statistics)는 영업이 끝난 뒤 앉아서 이렇게 요약하는 것입니다.
“평균 대기 시간은 18분이었다. 가장 짧게 기다린 사람은 6분, 가장 오래 기다린 사람은 45분이었다. 대부분의 고객은 14분에서 22분 사이에 피자를 받았다.”
즉, 실제로 일어난 일을 있는 그대로 설명하는 것입니다. 그 이상도, 그 이하도 아닙니다.
반면 추론통계(Inferential Statistics)는 여기서 한 걸음 더 나아가 이런 질문을 던집니다.
“오늘 결과를 바탕으로 다음 주 토요일은 어떻게 될지 예측할 수 있을까? 새로 들인 오븐이 실제로 배달 시간을 줄인 걸까, 아니면 단순히 운이 좋았던 걸까?”
즉, 관측한 데이터를 넘어 더 큰 세계에 대해 결론을 내리는 과정입니다. 작은 표본을 이용해 더 넓은 모집단을 이해하려는 시도입니다.
하나는 뒤를 돌아봅니다.
다른 하나는 앞으로 내다봅니다.
그리고 둘 다 반드시 필요합니다.
Part 1: 기술통계 — 현실을 요약하는 기술
“통계학은 과학의 문법이다.” — 현대 통계학의 창시자 칼 피어슨(Karl Pearson)
기술통계(Descriptive Statistics)는 방대한 양의 데이터를 이해하기 쉬운 형태로 압축해주는 도구를 제공합니다. 데이터셋의 핵심 장면만 모아 보여주는 하이라이트 영상이라고 생각하면 됩니다.
기술통계의 세 가지 축
1. 중심 경향성(Central Tendency) — 데이터는 어디에 모여 있는가?
- 평균(Mean): 산술평균
- 중앙값(Median): 데이터를 정렬했을 때 가운데 위치한 값
- 최빈값(Mode): 가장 자주 등장하는 값
2. 산포도(Dispersion) — 데이터는 얼마나 퍼져 있는가?
- 범위(Range): 최대값 − 최소값
- 분산(Variance): 평균으로부터의 제곱 편차의 평균
- 표준편차(Standard Deviation): 분산의 제곱근 (원래 데이터와 같은 단위를 가짐)
- 사분위 범위(Interquartile Range, IQR): 가운데 50% 데이터가 분포하는 범위
3. 형태와 분포(Shape & Distribution) — 데이터는 어떤 모습을 하고 있는가?
- 왜도(Skewness): 분포의 꼬리가 왼쪽 또는 오른쪽으로 더 길게 늘어져 있는가?
- 첨도(Kurtosis): 꼬리가 두껍고 극단값이 많은 분포인가, 아니면 얇고 안정적인 분포인가?
- 히스토그램(Histogram), 박스플롯(Box Plot), 밀도 곡선(Density Curve): 분포를 시각적으로 요약하는 도구
기술통계의 목표는 데이터를 설명하는 것입니다. 복잡한 현실을 몇 개의 숫자와 그림으로 압축해, 사람이 이해할 수 있는 형태로 바꾸는 것이죠.
Part 2: 추론통계 — 근거 있는 추정을 하는 기술
“모든 모델은 틀리지만, 어떤 모델은 유용하다.”— 통계학자 조지 E. P. 박스(George E. P. Box)
기술통계가 하나의 사진이라면, 추론통계(Inferential Statistics)는 아직 찍지 않은 사진들에 대해 예측하는 일입니다.
이것이 가능한 이유는 매우 아름다운 아이디어 하나에 기반합니다. 데이터를 무작위(random)이고 대표성 있게 표본 추출했다면, 그 표본 안에는 그것이 속한 모집단(population)에 대한 정보가 담겨 있다는 것입니다.
핵심 개념
모집단(Population)과 표본(Sample)
- 모집단(Population): 우리가 관심을 가지는 전체 대상
(예: 대한민국 전체 성인 인구) - 표본(Sample): 실제로 관측하거나 측정한 일부 집단
(예: 설문에 응답한 1,000명)
가설 검정(Hypothesis Testing)
먼저 하나의 주장(가설)을 세운 뒤, 데이터를 이용해 그 주장을 유지할지 기각할지 판단합니다.
- 귀무가설(Null Hypothesis, H₀)
“특별한 변화나 효과가 없다”
(예: 새로운 약은 효과가 없다) - 대립가설(Alternative Hypothesis, H₁)
“의미 있는 변화나 효과가 있다”
(예: 새로운 약은 실제 효과가 있다) - p값(p-value)
귀무가설이 참이라고 가정했을 때, 지금과 같은 결과가 관측될 확률입니다. - 일반적으로 p값 < 0.05이면 관측된 결과가 단순한 우연만으로 발생했을 가능성이 낮다고 판단합니다.
신뢰구간(Confidence Interval)
추론통계는 하나의 숫자를 단정적으로 말하기보다 불확실성을 함께 제시합니다.
예를 들어,
“평균 소득은 5만 2천 달러다.”
대신
“실제 평균 소득은 95% 신뢰수준에서 4만 9,500달러 ~ 5만 4,500달러 사이에 존재한다고 추정한다.”
이러한 표현은 결과의 불확실성을 정직하게 인정하는 방식입니다.
대표적인 통계 검정 방법
검정 방법사용 목적
| t-검정 (t-test) | 두 집단의 평균 차이를 비교 |
| 분산분석 (ANOVA) | 세 개 이상의 집단 평균 차이를 비교 |
| 카이제곱 검정 (Chi-square Test) | 범주형 변수 간의 관계 또는 독립성 검정 |
| 피어슨 / 스피어만 상관분석 (Pearson / Spearman) | 변수 간 상관관계 측정 |
| 선형 회귀 (Linear Regression) | 연속형 결과값 예측 |
Part 3: 무엇이 다른가?
차원 (Dimension)기술통계 (Descriptive Statistics)추론통계 (Inferential Statistics)| 목적 (Purpose) | 현재 존재하는 데이터를 요약 | 미래를 예측하거나, 관측된 데이터를 바탕으로 더 넓은 대상을 추론 |
| 범위 (Scope) | 현재 보유한 전체 데이터셋 자체 | 표본 → 더 넓은 모집단 |
| 불확실성 (Uncertainty) | 없음 — 실제로 일어난 일을 그대로 설명 | 항상 불확실성을 포함 |
| 산출물 (Output) | 평균, 중앙값, 차트, 표 | p값, 신뢰구간, 예측 |
| 던지는 질문 (Question asked) | “무슨 일이 일어났는가?” | “이것이 더 큰 관점에서는 무엇을 의미하는가?” |
| 예시 (Example) | “지난달 사용자 중 18%가 이탈했다” | “새로운 기능이 실제로 사용자 이탈 감소를 유발하고 있는가?” |
기술통계를 의사가 환자의 활력 징후를 측정하는 과정이라고 생각해봅시다. 맥박, 체온, 혈압을 측정하는 것이 여기에 해당합니다.
추론통계는 의사가 이렇게 말하는 단계입니다.
“이 측정 결과를 바탕으로 볼 때, 당신은 X일 가능성이 있으며, 따라서 우리는 이렇게 치료해야 합니다.”
Part 4: 이 둘은 어떻게 연결되는가?
대부분의 입문자가 놓치는 점이 하나 있습니다. 기술통계 없이 추론통계를 할 수는 없습니다.
기술통계는 항상 출발점입니다. 먼저 표본 데이터를 요약합니다. 그리고 그다음에 추론통계를 통해 그 요약 결과를 더 넓은 모집단으로 일반화합니다.
그 흐름은 다음과 같습니다:
Raw Data → Descriptive Stats (summarize) → Inferential Stats (generalize)
↓ ↓
"Here's what our sample looks like" "Here's what this tells us about
the world beyond our sample"
이 둘은 동전의 양면과 같습니다. 모든 추론통계적 주장은 기술통계라는 기반 위에 세워집니다. 그리고 모든 기술통계적 요약은 자연스럽게 다음 질문으로 이어집니다.
“그렇다면 이것은 더 넓은 관점에서 어떤 의미를 가지는가?”
Part 5: 데이터셋 — 아이리스(Iris) 꽃 데이터 (오랫동안 사랑받아온 데에는 이유가 있다)
이번에는 통계학자 로널드 피셔(Ronald Fisher)가 1936년에 소개한 전설적인 아이리스(Iris) 데이터셋을 사용해보겠습니다. 이 데이터셋은 세 가지 품종의 붓꽃(Setosa, Versicolor, Virginica) 총 150개 샘플에 대한 측정값을 포함하고 있습니다.
각 꽃은 다음 네 가지 측정값을 가지고 있습니다.
- Sepal length (cm)
- Sepal width (cm)
- Petal length (cm)
- Petal width (cm)
왜 아이리스 데이터일까요?
이 데이터는 깔끔하고, 실제 데이터를 기반으로 하며, 생물학적 의미를 가지고 있고, 동시에 기술통계와 추론통계를 모두 아름답게 설명하기에 충분히 풍부하기 때문입니다.
Part 6: 실습 코드 — 아이리스 데이터로 기술통계 수행하기
# ============================================================
# DESCRIPTIVE STATISTICS ON THE IRIS DATASET
# ============================================================
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
# Load the dataset
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
print("Shape of dataset:", df.shape)
print("\nFirst 5 rows:")
print(df.head())
Shape of dataset: (150, 5)
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosaSummary Statistics
# ---------------------------------------------------------
# THE GRAND SUMMARY — describe() gives the full picture
# ---------------------------------------------------------
print("\n📊 Descriptive Statistics:")
print(df.describe().round(2))
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50더 깊이 들어가기 — 품종별 기술통계 분석
# ---------------------------------------------------------
# SPECIES-LEVEL DESCRIPTIVE BREAKDOWN
# ---------------------------------------------------------
print("\n🌸 Mean measurements per species:")
print(df.groupby('species').mean().round(2))
🌸 Mean measurements per species:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
species
setosa 5.01 3.43 1.46 0.25
versicolor 5.94 2.77 4.26 1.33
virginica 6.59 2.97 5.55 2.03
# Measure spread
print("\n📐 Standard Deviation per species:")
print(df.groupby('species').std().round(2))
📐 Standard Deviation per species:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
species
setosa 0.35 0.38 0.17 0.11
versicolor 0.52 0.31 0.47 0.20
virginica 0.64 0.32 0.55 0.27
여기서도 기술통계는 하나의 이야기를 들려주고 있습니다. Setosa는 Virginica에 비해 꽃잎 길이가 훨씬 작습니다. (평균 1.46cm 대비 5.55cm)
즉, 이들 품종은 측정 가능한 수준에서 서로 다른 특성을 가지고 있습니다.
분포 시각화하기
# ---------------------------------------------------------
# VISUALIZING DESCRIPTIVE STATISTICS
# ---------------------------------------------------------
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle('Iris Dataset — Descriptive Statistics Visualization',
fontsize=16, fontweight='bold')
features = iris.feature_names
colors = ['#E74C3C', '#3498DB', '#2ECC71']
for idx, ax in enumerate(axes.flat):
feature = features[idx]
for i, species in enumerate(iris.target_names):
subset = df[df['species'] == species][feature]
ax.hist(subset, alpha=0.6, bins=15, color=colors[i], label=species)
ax.axvline(subset.mean(), color=colors[i], linestyle='--', linewidth=1.5)
ax.set_title(f'Distribution of {feature}')
ax.set_xlabel(feature)
ax.set_ylabel('Frequency')
ax.legend()
plt.tight_layout()
plt.savefig('iris_descriptive.png', dpi=150)
plt.show()
print("✅ Distribution plots saved.")
박스플롯(Box Plot) — 데이터의 퍼짐과 이상치 찾기
# ---------------------------------------------------------
# BOX PLOTS: The Swiss Army Knife of Descriptive Statistics
# ---------------------------------------------------------
fig, axes = plt.subplots(1, 4, figsize=(16, 6))
fig.suptitle('Box Plots by Species — Spread & Outliers',
fontsize=14, fontweight='bold')
for idx, feature in enumerate(features):
sns.boxplot(data=df, x='species', y=feature,
palette=['#E74C3C', '#3498DB', '#2ECC71'], ax=axes[idx])
axes[idx].set_title(feature)
axes[idx].set_xlabel('')
plt.tight_layout()
plt.savefig('iris_boxplots.png', dpi=150)
plt.show()
print("✅ Box plots saved.")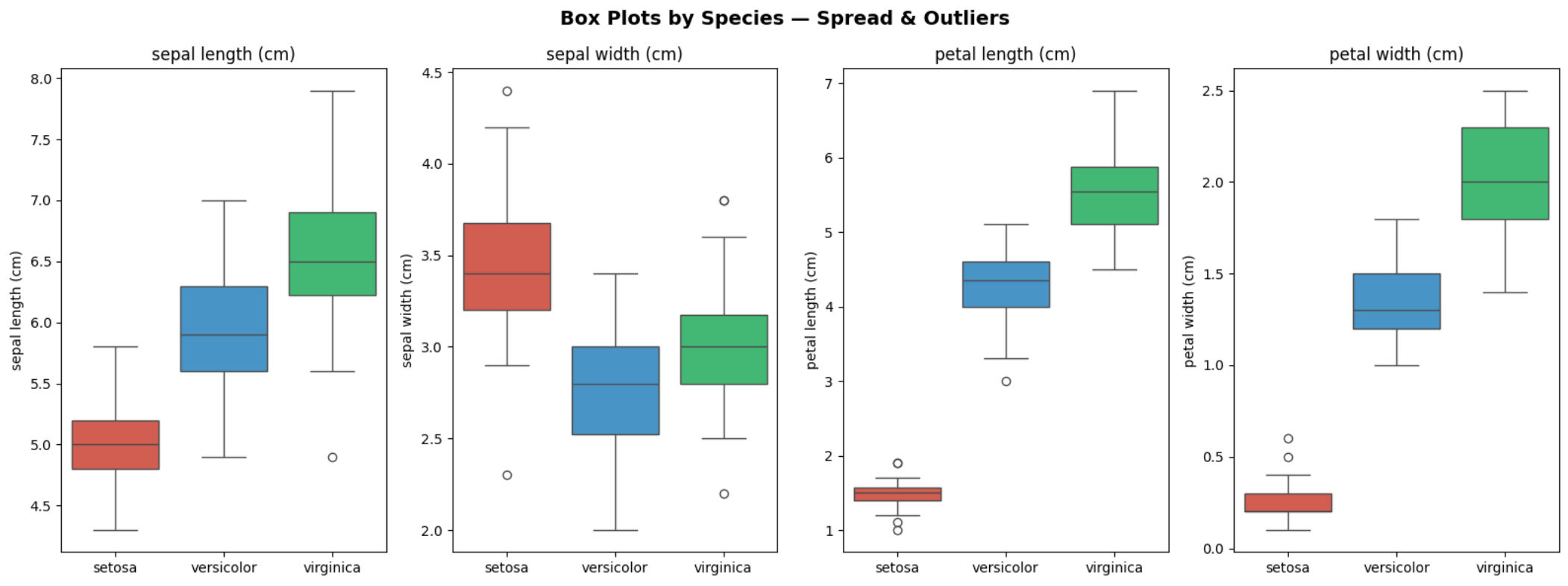
상관관계 히트맵 (Correlation Heatmap)
# ---------------------------------------------------------
# CORRELATION MATRIX — How features relate to each other
# ---------------------------------------------------------
corr_matrix = df[features].corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix,
annot=True,
fmt='.2f',
cmap='RdYlGn',
center=0,
linewidths=0.5,
cbar_kws={'shrink': 0.8})
plt.title('Feature Correlation Matrix — Iris Dataset',
fontsize=13, fontweight='bold', pad=15)
plt.tight_layout()
plt.savefig('iris_correlation.png', dpi=150)
plt.show()
print("\n🔍 Key correlations:")
print(corr_matrix.round(2))
꽃잎 길이(Petal length)와 꽃잎 너비(Petal width)의 상관계수가 0.96이라는 점에 주목해보세요. 이는 거의 완벽에 가까운 상관관계를 의미합니다.
이러한 정보는 머신러닝에서 특성 선택(Feature Selection) 을 수행할 때 매우 유용하게 활용됩니다.
Part 7: 실습 코드 — 아이리스 데이터로 추론통계 수행하기
이제 데이터를 설명하는 단계에서 나아가, 데이터를 바탕으로 추론을 수행하는 단계로 이동해보겠습니다.
가설 검정 1: t-검정(t-Test) — 이 품종들은 정말로 서로 다른가?
# ============================================================
# INFERENTIAL STATISTICS ON THE IRIS DATASET
# ============================================================
from scipy import stats
# ---------------------------------------------------------
# t-TEST: Is petal length significantly different between
# Setosa and Virginica?
# ---------------------------------------------------------
setosa_petal = df[df['species'] == 'setosa']['petal length (cm)']
virginica_petal = df[df['species'] == 'virginica']['petal length (cm)']
t_stat, p_value = stats.ttest_ind(setosa_petal, virginica_petal)
print("=" * 55)
print(" t-TEST: Setosa vs Virginica Petal Length")
print("=" * 55)
print(f" Setosa mean petal length: {setosa_petal.mean():.2f} cm")
print(f" Virginica mean petal length: {virginica_petal.mean():.2f} cm")
print(f" t-statistic: {t_stat:.4f}")
print(f" p-value: {p_value:.2e}")
print()
if p_value < 0.05:
print("✅ Result: SIGNIFICANT difference (p < 0.05)")
print(" We REJECT the null hypothesis.")
print(" The species are genuinely different — not by luck.")
else:
print("❌ Result: No significant difference (p >= 0.05)")
print("=" * 55)
=======================================================
t-TEST: Setosa vs Virginica Petal Length
=======================================================
Setosa mean petal length: 1.46 cm
Virginica mean petal length: 5.55 cm
t-statistic: -49.9862
p-value: 1.50e-71
✅ Result: SIGNIFICANT difference (p < 0.05)
We REJECT the null hypothesis.
The species are genuinely different — not by luck.
=======================================================p값(p-value)이 4.40e-86이라는 것은 사실상 0에 가깝다는 의미입니다. 즉, 이 두 품종 간의 차이는 우연히 발생한 것이 아니라 실제로 존재하는 차이라고 볼 수 있습니다.
가설 검정 2: ANOVA — 세 가지 품종 모두 비교하기
# ---------------------------------------------------------
# ANOVA: Are all three species different in sepal length?
# (Use when comparing 3+ groups)
# ---------------------------------------------------------
setosa_sepal = df[df['species'] == 'setosa']['sepal length (cm)']
versicolor_sepal = df[df['species'] == 'versicolor']['sepal length (cm)']
virginica_sepal = df[df['species'] == 'virginica']['sepal length (cm)']
f_stat, p_value_anova = stats.f_oneway(setosa_sepal, versicolor_sepal, virginica_sepal)
print("=" * 55)
print(" ANOVA: Sepal Length Across All 3 Species")
print("=" * 55)
print(f" F-statistic: {f_stat:.4f}")
print(f" p-value: {p_value_anova:.2e}")
print()
if p_value_anova < 0.05:
print("✅ At least one species has a significantly")
print(" different mean sepal length.")
print("=" * 55)
=======================================================
ANOVA: Sepal Length Across All 3 Species
=======================================================
F-statistic: 119.2645
p-value: 1.67e-31
✅ At least one species has a significantly
different mean sepal length.
=======================================================신뢰구간 (Confidence Intervals)
# ---------------------------------------------------------
# CONFIDENCE INTERVALS
# "We are 95% confident the true mean falls within..."
# ---------------------------------------------------------
def confidence_interval(data, confidence=0.95):
n = len(data)
mean = np.mean(data)
se = stats.sem(data) # Standard error of the mean
h = se * stats.t.ppf((1 + confidence) / 2., n - 1)
return mean, mean - h, mean + h
print("\n📏 95% Confidence Intervals for Petal Length by Species:")
print("-" * 60)
for species in iris.target_names:
data = df[df['species'] == species]['petal length (cm)']
mean, lower, upper = confidence_interval(data)
print(f" {species:>12}: {mean:.2f} cm [95% CI: {lower:.2f} – {upper:.2f}]")
print("-" * 60)
📏 95% Confidence Intervals for Petal Length by Species:
------------------------------------------------------------
setosa: 1.46 cm [95% CI: 1.41 – 1.51]
versicolor: 4.26 cm [95% CI: 4.13 – 4.39]
virginica: 5.55 cm [95% CI: 5.40 – 5.71]
------------------------------------------------------------
서로 겹치지 않는 이러한 신뢰구간은 앞서 t-검정에서 확인했던 결과를 다시 뒷받침해줍니다. 즉, 이 품종들은 실제로, 그리고 통계적으로 검증 가능한 수준에서 서로 다르다는 것을 보여줍니다.
선형 회귀 (Linear Regression) — 관계 추론하기
# ---------------------------------------------------------
# LINEAR REGRESSION: Can sepal length predict petal length?
# ---------------------------------------------------------
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_squared_error
X = df[['sepal length (cm)']].values
y = df['petal length (cm)'].values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print("=" * 55)
print(" LINEAR REGRESSION: Sepal → Petal Length")
print("=" * 55)
print(f" Coefficient (slope): {model.coef_[0]:.4f}")
print(f" Intercept: {model.intercept_:.4f}")
print(f" R² Score: {r2:.4f}")
print(f" RMSE: {rmse:.4f} cm")
print()
print(" Interpretation:")
print(f" For every 1 cm increase in sepal length,")
print(f" petal length increases by {model.coef_[0]:.2f} cm on average.")
print("=" * 55)
=======================================================
LINEAR REGRESSION: Sepal → Petal Length
=======================================================
Coefficient (slope): 1.8340
Intercept: -6.9271
R² Score: 0.8181
RMSE: 0.7721 cm
Interpretation:
For every 1 cm increase in sepal length,
petal length increases by 1.83 cm on average.
=======================================================Part 8: 이것이 머신러닝과 어떻게 연결되는가
“머신러닝은 본질적으로 통계학이며, 단지 컴퓨터가 대부분의 계산을 대신 수행하는 것이다.”
— Sebastian Raschka, 『Machine Learning with PyTorch and Scikit-Learn』 저자
이제 모든 것이 하나로 연결됩니다. 머신러닝은 통계학과 별개의 분야가 아닙니다. 머신러닝은 통계학이며, 여기에 강력한 계산 능력이 더해진 형태입니다.
머신러닝에서의 기술통계 (Descriptive Statistics)
| 탐색적 데이터 분석 (EDA) | 모델링 전에 데이터셋을 이해하기 위해 사용 |
| 특성 엔지니어링 (Feature Engineering) | 통계적 요약 정보를 기반으로 새로운 특성을 생성 |
| 정규화 (Normalization) | 평균과 표준편차를 사용하여 특성의 스케일 조정 (StandardScaler) |
| 이상치 탐지 (Outlier Detection) | IQR 또는 z-score를 사용해 이상값 탐지 |
| 클래스 불균형 탐지 (Class Imbalance Detection) | 타깃 변수의 분포를 확인하여 클래스 불균형 여부 분석 |
머신러닝에서의 추론통계 (Inferential Statistics)
| 모델 평가 (Model Evaluation) | 내 모델의 성능 향상이 통계적으로 유의미한가? |
| A/B 테스트 (A/B Testing) | 새로운 추천 알고리즘이 실제로 클릭률(CTR)을 개선했는가? |
| 특성 선택 (Feature Selection) | 어떤 특성이 타깃 변수와 통계적으로 상관관계를 가지는가? |
| 하이퍼파라미터 튜닝 (Hyperparameter Tuning) | 두 모델 설정 간의 차이가 실제 효과인가, 아니면 잡음인가? |
| 예측에 대한 신뢰도 (Confidence in Predictions) | 예측 구간(Prediction Intervals), 베이지안 추론(Bayesian Inference) |
# ---------------------------------------------------------
# ML CONTEXT: Using descriptive stats for preprocessing
# (StandardScaler uses mean and std — descriptive statistics!)
# ---------------------------------------------------------
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
X_features = df[features].values
# StandardScaler: subtracts mean, divides by std deviation
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_features)
print("Before scaling (sepal length):")
print(f" Mean: {X_features[:, 0].mean():.2f}, Std: {X_features[:, 0].std():.2f}")
print("\nAfter scaling (sepal length):")
print(f" Mean: {X_scaled[:, 0].mean():.4f}, Std: {X_scaled[:, 0].std():.4f}")
print("\n✅ StandardScaler uses descriptive statistics (mean, std)")
print(" to transform data for ML models.")
Before scaling (sepal length):
Mean: 5.84, Std: 0.83
After scaling (sepal length):
Mean: -0.0000, Std: 1.0000
✅ StandardScaler uses descriptive statistics (mean, std)
to transform data for ML models.
매번 StandardScaler()를 호출할 때마다, 여러분은 기술통계(Descriptive Statistics) 를 적용하고 있는 것입니다.
이 알고리즘은 학습 데이터의 평균(mean) 과 표준편차(standard deviation) 를 계산하고, 이를 사용해 특성(feature)을 변환합니다.
즉, 통계학이 머신러닝을 움직이고 있는 것입니다.
Part 9: 머릿속 지도 — 모든 것을 하나로 연결하기
THE STATISTICS → ML PIPELINE
📥 RAW DATA (Iris: 150 flowers, 4 features, 3 species)
↓
📊 DESCRIPTIVE STATISTICS
• Mean, median, std, IQR per feature
• Distribution shapes (histograms)
• Correlation matrix
• Box plots for outliers
↓
🔍 INFERENTIAL STATISTICS
• t-tests: Are species truly different?
• ANOVA: Across all three species?
• Confidence intervals: How certain are we?
• Regression: Can one feature predict another?
↓
🤖 MACHINE LEARNING
• Preprocessing (uses mean, std from descriptive stats)
• Feature selection (uses p-values from inferential stats)
• Model training (learns statistical patterns)
• Model evaluation (A/B tests, significance testing)
↓
💡 DECISIONS & INSIGHTS
Part 10: 초보자가 자주 하는 실수들
실수 1: 평균이 모든 것을 설명한다고 생각하기
“우리 회사의 평균 연봉은 8만 달러입니다.”
그럴듯하게 들립니다. 하지만 CEO가 200만 달러를 받고 있고 직원의 90%가 4만 달러를 받고 있다는 사실을 알게 되면 이야기가 달라집니다. 평균은 이상치(outlier)에 의해 쉽게 왜곡될 수 있습니다. 항상 중앙값(median) 과 분포(distribution) 도 함께 확인하세요.
실수 2: 상관관계를 인과관계로 착각하기
꽃잎 길이와 꽃잎 너비의 상관계수는 96%입니다. 하지만 이것이 한 변수가 다른 변수를 만들어낸다는 뜻은 아닙니다. 둘 다 품종의 유전적 특성에 의해 함께 영향을 받는 것입니다.
유명한 예가 있습니다.
“아이스크림 판매량과 익사 사고율은 상관관계가 있다.”
하지만 그렇다고 해서 아이스크림이 사람을 익사하게 만드는 것은 아닙니다.
실수 3: p-해킹(p-hacking)
p < 0.05가 나올 때까지 20개의 서로 다른 검정을 반복하는 것은 과학이 아닙니다. 그것은 도박에 가깝습니다.
여러 번의 비교를 수행할 때는 Bonferroni 보정이나 FDR(False Discovery Rate) 방법 등을 사용해 다중 비교 문제를 조정해야 합니다.
실수 4: 효과 크기(effect size)를 무시하기
p값은 결과가 유의한지 알려줍니다. 하지만 얼마나 중요한지는 알려주지 않습니다.
예를 들어 어떤 약이 p = 0.001이라는 매우 강한 유의성을 보여도 실제 증상을 단지 0.1%만 감소시킬 수도 있습니다.
항상 p값과 함께 효과 크기(effect size) 를 함께 보고하세요.
실수 5: 가정을 확인하지 않기
대부분의 통계 검정에는 전제가 존재합니다. 예를 들면 정규성(normality), 등분산성(equal variances), 독립성(independence) 등이 있습니다.
이런 가정을 확인하지 않고 분석을 진행하는 것은 지반을 확인하지 않고 집을 짓는 것과 같습니다.
결론: 데이터 과학을 움직이는 두 가지 질문
여러분이 앞으로 커리어에서 수행하게 될 모든 분석은 결국 두 가지 질문으로 귀결됩니다.
“무슨 일이 일어났는가?” — 기술통계가 이 질문에 답합니다.
“그것이 무엇을 의미하는가?” — 추론통계가 이 질문에 답합니다.
오늘 우리가 분석한 아이리스 꽃 데이터는 단순한 식물학적 흥미거리가 아닙니다. 그것은 하나의 은유입니다. 앞으로 여러분이 만나게 될 모든 데이터셋 — 고객 행동 데이터, 임상시험 결과, 주가 데이터, 소셜 미디어 참여 데이터 등 — 은 결국 동일한 두 가지 질문을 던집니다. 여러분의 역할은 그 질문에 정직함(honesty), 엄밀함(rigor), 그리고 명확함(clarity) 으로 답하는 것입니다.
통계학은 종종 건조하고 수학적인 학문처럼 가르쳐집니다. 하지만 그 본질은 호기심(curiosity) 에 있습니다. 세상을 있는 그대로 받아들이지 않고, 눈앞의 결과가 실제인지 우연인지 질문하는 것, 불확실성을 인정할 만큼 겸손하면서도 그럼에도 결론을 내릴 만큼 용기 있는 태도에 있습니다.
“그림의 가장 큰 가치는 우리가 결코 보지 못할 것이라 생각했던 것을 보게 만든다는 데 있다.”
— 수학자이자 통계학자 존 터키(John Tukey)
다음번에 식당의 평점을 확인하거나, 백신 효능 보고서를 읽거나, 머신러닝 모델의 정확도를 해석하게 될 때 — 여러분은 그 이면에서 어떤 사고 과정이 작동하고 있는지 정확히 이해하게 될 것입니다.
그리고 그 이해는 모든 것을 바꿉니다.
이제 데이터를 탐험해보세요. 어떤 데이터든 좋습니다.
먼저 물어보세요.
무슨 일이 일어났는가?
그리고 이어서 물어보세요.
그것은 무엇을 의미하는가?
'통계의 기초' 카테고리의 다른 글
| e와 로그 — 직관적으로 이해하기 (0) | 2026.05.30 |
|---|---|
| Z-검정과 T-검정의 모든 것 (0) | 2026.05.29 |
| 통계에서 정규성을 검증하는 세 가지 방법 (0) | 2026.05.26 |
| 경영 의사 결정을 위한 가설 검정 - Part 2 (0) | 2026.05.17 |
| 확률(Probability) vs. 가능성(우도, Likelihood) (0) | 2026.05.14 |



댓글