넷플릭스가 당신의 홈페이지 썸네일을 바꿀 때마다, 그 결정 뒤에는 통계적 검정이 있습니다. 디자이너의 직감이 아닙니다. 회의에서 나온 관리자의 의견도 아닙니다. 검정입니다. 그들은 버전 A를 수십만 명의 사용자에게 보여주고, 버전 B를 또 다른 수십만 명의 사용자에게 보여준 뒤, 누가 클릭했는지 세고, 수학이 논쟁을 끝내게 합니다.
당신의 약장에 있는 모든 약도 FDA가 “좋아요, 판매하세요”라고 말하기 전에 같은 종류의 검정을 통과했습니다. 인스타그램이 피드의 순서를 조금 바꿀 때마다도 마찬가지입니다. 교사가 새로운 수업 방식이 실제로 효과가 있었는지 궁금해할 때도 마찬가지입니다.
당신은 통계적 추론 한가운데 깊숙이 들어와 있습니다. 아직 그 어휘를 갖고 있지 않을 뿐입니다.
그것이 바로 지금부터 바뀝니다. 우리는 아무것도 모르는 상태에서 출발해 z-검정, t-검정, p-값, 가설 검정, 신뢰구간, 그리고 그들이 던져댈 모든 그리스 문자까지 진짜로 이해하는 단계까지 갈 것입니다. 저는 실제 파이썬 코드를 작성하고 모든 줄을 하나하나 설명할 것입니다. 이해되는 실제 예제를 사용할 것입니다. 그리고 여러분이 학교에서 배운 내용을 기억한다고 가정하지 않겠습니다.
시작하기 전에 규칙 하나만 정하겠습니다. 어떤 문장에 당신이 모르는 단어가 나온다면, 그것은 당신 잘못이 아니라 제 잘못입니다. 저는 그 단어를 즉시 설명해야 합니다. 그렇지 않다면 애초에 사용하지 말았어야 합니다.
시작해봅시다.
핵심 아이디어 (30초 만에 이해하기)
당신은 인도 전체 인구의 평균 키를 알고 싶다고 가정해 봅시다. 14억 명 전부의 평균 키 말입니다. 직접 인도로 가서 줄자를 들고 앞으로 40년 동안 집집마다 방문하며 측정할 수도 있습니다. 아니면 무작위로 500명을 측정한 뒤, 나머지 1,399,999,500명에 대해서는 합리적인 추정을 할 수도 있습니다.
이것이 바로 통계적 추론(statistical inference)입니다. 사실상 이 분야 전체를 한 문장으로 요약한 것입니다. 전체의 작은 일부를 관찰하고, 그것을 바탕으로 전체에 대해 신중하고 수학적으로 근거 있는 결론을 내리는 것입니다.
이 작은 일부를 표본(sample)이라고 합니다. 전체를 모집단(population)이라고 합니다. 그리고 표본에서 모집단으로 넘어가는 과정(물론 얼굴부터 바닥에 떨어지지 않도록 안전장치를 갖춘 상태에서)을 추론(inference)이라고 부릅니다.
이 글에서 다루는 모든 검정, 공식, 개념은 결국 하나의 질문에 답하기 위해 존재합니다.
“내가 가진 작은 표본이 전체 그림에 대해 말해주는 내용을 믿어도 될까?”
그것이 유일한 질문입니다. 나머지는 모두 그 질문에 답하기 위한 도구일 뿐입니다.

모집단, 표본, 그리고 사람들을 겁먹게 만드는 그리스 문자들
먼저 용어부터 정리해 봅시다. 생각보다 훨씬 간단합니다.
모집단(Population)은 당신이 관심 있는 집단의 모든 구성원을 의미합니다. 모든 고객, 모든 환자, 공장에서 생산되는 모든 배터리 등이 여기에 해당합니다. 통계학에서는 모집단의 크기를 대문자 N으로 나타냅니다. 그리고 모집단의 특성을 표현할 때는 그리스 문자를 사용합니다. 모집단의 평균은 μ(뮤, mu), 모집단의 산포도(퍼짐 정도)는 σ(시그마, sigma)로 표시합니다.
표본(Sample)은 실제로 측정한 더 작은 집단입니다. 표본의 크기는 소문자 n으로 나타냅니다. 그리고 표본의 측정값에는 일반적인 문자들을 사용합니다. 표본 평균은 x̄(x-bar, 엑스 바), 표본의 산포도는 s로 표시합니다.
이 글의 나머지 내용을 이해하는 데 필요한 핵심 요약표는 다음과 같습니다.
+--------------------+--------------------+-------------------+
| What | Population | Sample |
+--------------------+--------------------+-------------------+
| Average | μ (mu) | x-bar |
| Spread | σ (sigma) | s |
| How many | N | n |
+--------------------+--------------------+-------------------+
그리스 문자는 모집단을 나타내고, 일반 문자는 표본을 나타냅니다. 그것이 전부입니다. 계속 읽다 보면 자연스럽게 익숙해질 것입니다.
표준편차(Standard Deviation): 아무도 제대로 설명해 주지 않는 가장 유용한 숫자
어떤 검정을 배우기 전에 반드시 표준편차를 이해해야 합니다. 앞으로 살펴볼 거의 모든 공식에 표준편차가 등장하기 때문입니다. 하지만 대부분의 글은 단순히 σ라는 기호만 던져주고 넘어갑니다. 저는 그러지 않겠습니다.
다섯 명의 친구가 자신의 월세를 비교하고 있다고 상상해 봅시다.
A는 1,000달러를 냅니다. B는 1,050달러, C는 1,100달러, D는 1,150달러, E는 1,200달러를 냅니다.
평균 월세는 1,100달러입니다. 이제 각 사람이 평균에서 얼마나 떨어져 있는지 살펴보겠습니다.
A는 평균보다 100달러 적게 냅니다. B는 50달러 적게 냅니다. C는 평균과 정확히 같습니다. D는 50달러 더 냅니다. E는 100달러 더 냅니다.
이 거리들을 평균 내되, 음수와 양수를 처리하기 위해 중간에 제곱을 하고 마지막에 다시 제곱근을 취하면 표준편차를 얻을 수 있습니다. 이 집단의 표준편차는 약 70.71달러입니다.
표준편차는 평균으로부터의 평균적인 거리입니다. 이것이 가장 쉬운 설명입니다. 표준편차가 작으면 사람들이 평균 근처에 모여 있다는 뜻이고, 표준편차가 크면 값들이 넓게 퍼져 있다는 뜻입니다.
이제 다른 다섯 명의 친구를 생각해 봅시다. 이들의 월세는 각각 200달러, 600달러, 1,100달러, 1,600달러, 그리고 2,000달러입니다. 평균은 여전히 1,100달러로 같지만 분포는 완전히 다릅니다. 이 경우 표준편차는 약 640달러입니다.
중심은 같습니다. 하지만 이야기는 완전히 다릅니다. 표준편차는 바로 그 “완전히 다른 이야기”를 숫자로 표현해 줍니다.
이것이 왜 통계 검정에서 중요할까요?
z-검정이나 t-검정을 수행할 때 우리는 다음과 같은 질문을 합니다.
“내 표본 평균이 기대되는 값에서 충분히 멀리 떨어져 있어서 의심할 만한 수준인가?”
그런데 여기서 “충분히 멀다”는 기준은 데이터가 얼마나 퍼져 있는지에 전적으로 달려 있습니다.
표본 평균이 모집단 평균에서 10만큼 떨어져 있다고 해봅시다.
만약 σ가 5라면 이는 매우 큰 차이입니다.
반대로 σ가 500이라면 사실상 아무 의미도 없는 차이입니다.
표준편차는 “얼마나 멀리 떨어져 있는가”를 측정하는 자와 같습니다.
정규분포(Bell Curve): 왜 통계의 거의 모든 것이 이것을 중심으로 돌아가는가
무작위로 선택한 성인 10,000명의 키를 그래프로 그려 봅시다. 대부분의 사람들은 평균 근처에 모여 있습니다. 평균보다 조금 더 크거나 조금 더 작은 사람들은 그보다 적습니다. 매우 크거나 매우 작은 사람들은 극히 드뭅니다. 이렇게 만들어지는 형태는 매끄럽고 대칭적인 언덕 모양입니다.
이 형태를 정규분포(Normal Distribution)라고 합니다. 흔히 벨 곡선(Bell Curve)이라고도 부릅니다.

전체 데이터의 약 68%가 평균을 중심으로 한 표준편차 1개 범위 안에 존재합니다. 이 사실 하나만으로도 통계학의 절반을 설명할 수 있습니다.
이 분포가 특별한 이유는 세 가지입니다.
대칭적입니다. 왼쪽은 오른쪽의 거울상입니다. 평균보다 작은 사람의 수와 평균보다 큰 사람의 수가 거의 같습니다.
평균이 꼭대기에 위치합니다. 언덕의 가장 높은 지점이 평균값입니다. 대부분의 데이터는 이 주변에 존재합니다.
68–95–99.7 법칙이 적용됩니다. 이것이 정규분포의 가장 강력한 특징입니다. 전체 데이터의 약 68%는 평균으로부터 표준편차 1개 이내에 존재합니다. 약 95%는 표준편차 2개 이내에 존재합니다. 그리고 약 99.7%는 표준편차 3개 이내에 존재합니다.
구체적인 예를 들어보겠습니다. 성인의 평균 키가 170cm이고 표준편차가 10cm라고 가정해 봅시다. 그러면 성인의 약 68%는 160cm에서 180cm 사이에 존재합니다. 약 95%는 150cm에서 190cm 사이에 존재합니다. 그리고 약 99.7%는 140cm에서 200cm 사이에 존재합니다.
즉, 140cm보다 작거나 200cm보다 큰 사람을 만난다는 것은 약 1,000명 중 3명 정도를 만나는 수준의 일입니다. 매우 드문 경우입니다.
이것이 왜 중요할까요?
나중에 통계 검정을 수행했을 때 어떤 값이 평균에서 표준편차 3개만큼 떨어져 있다고 가정해 봅시다. 그러면 우리는 무언가 이상하다는 사실을 즉시 알 수 있습니다. 그런 정도의 차이는 우연히 발생할 확률이 0.3% 미만이기 때문입니다.
즉, 두 가지 가능성만 남습니다.
우리가 상상하기 어려울 정도로 운이 없었거나,
실제로 의미 있는 무언가가 일어나고 있거나.
이 직관이 바로 가설 검정(Hypothesis Testing)을 움직이는 핵심 엔진입니다.
이 개념은 꼭 기억해 두세요.
중심극한정리(Central Limit Theorem): 통계학이 가진 가장 기적에 가까운 법칙
이것은 이 글 전체에서 가장 중요한 개념입니다. 이 한 가지만 제대로 이해하면 나머지 모든 내용이 자연스럽게 연결됩니다.
상황을 하나 가정해 봅시다.
당신이 가진 모집단의 분포가 매우 이상한 모양이라고 해봅시다. 오른쪽으로 길게 꼬리가 늘어져 있을 수도 있고, 울퉁불퉁할 수도 있으며, 전혀 벨 곡선처럼 보이지 않을 수도 있습니다.
예를 들어 도시의 주택 가격 분포를 생각해 봅시다. 대부분의 집은 20만~40만 달러 수준이지만, 몇 채의 초고가 저택이 존재해 꼬리가 1,000만 달러까지 길게 늘어져 있습니다.
이제 다음 실험을 해보겠습니다.
무작위로 집 30채를 뽑습니다.
그 집들의 평균 가격을 계산합니다.
그 값을 기록합니다.
그리고 다시 반복합니다.
새로운 표본을 뽑고, 새로운 평균을 계산하고, 기록합니다.
이 과정을 1,000번 반복합니다.
이제 이렇게 얻은 1,000개의 평균값을 그래프로 그려보겠습니다.
놀랍게도 그 그래프는 벨 곡선 형태를 띠게 됩니다.
원래 데이터는 심하게 비대칭적이었음에도 말입니다.
이것이 바로 중심극한정리(Central Limit Theorem, CLT)입니다.
원래 모집단의 분포가 얼마나 이상한 모양이든 상관없이, 표본 크기가 충분히 커지면 표본평균들의 분포는 정규분포에 가까워집니다.
여기서 "충분히 크다"는 것은 일반적으로 n ≥ 30을 의미합니다.

왼쪽 위는 원래의 비대칭적인 데이터입니다.
오른쪽 아래는 충분한 수의 표본평균을 모았을 때의 모습입니다.
완벽한 벨 곡선입니다.
매번 그렇습니다.
이 변화 과정을 주목해 보세요.
원래 모집단은 지수분포(Exponential Distribution)로, 완전히 한쪽으로 치우쳐 있습니다.
하지만 표본 크기가 n = 30 정도만 되어도 표본평균의 분포는 상당히 아름다운 정규분포 형태를 보입니다.
n = 100이 되면 교과서에서 보는 정규분포와 거의 구분할 수 없을 정도가 됩니다.
왜 이것이 중요할까요?
중심극한정리는 우리가 실제 데이터가 정규분포를 따르지 않더라도 정규분포 기반의 수학을 사용할 수 있도록 허락해 주는 통계학의 면허증과 같습니다.
z-표, t-표, 그리고 모든 가설검정 공식들이 바로 이 원리에 기대고 있습니다.
만약 중심극한정리가 존재하지 않았다면, 우리는 통계 검정을 수행하기 전에 모든 데이터가 완벽한 벨 곡선 형태인지 확인해야 했을 것입니다.
하지만 현실의 데이터는 거의 정규분포를 따르지 않습니다.
중심극한정리는 이렇게 말합니다.
"상관없습니다. 원래 데이터는 이상해도, 표본평균들은 결국 정규분포가 될 테니까요."
이것이 바로 통계학에서 n ≥ 30이 마치 마법의 숫자처럼 반복해서 등장하는 이유입니다.
중심극한정리가 안정적으로 작동하기 시작하는 대표적인 기준점이기 때문입니다.
가설 검정(Hypothesis Testing). 사실 당신의 스팸 필터는 이미 이것을 알고 있다.
이메일 스팸 필터는 수신되는 모든 메시지에 대해 결정을 내립니다.
그 과정은 하나의 가정에서 시작됩니다.
"이 이메일은 아마 정상적인 이메일일 것이다."
그 다음 증거를 확인합니다.
발신자가 이상한가?
수상한 링크가 포함되어 있는가?
제목이 "무료로 돈을 드립니다!!!" 같은 ALL CAPS 문장인가?
만약 증거가 충분히 강하다면, 필터는 처음의 가정을 뒤집고 해당 메일을 스팸으로 분류합니다.
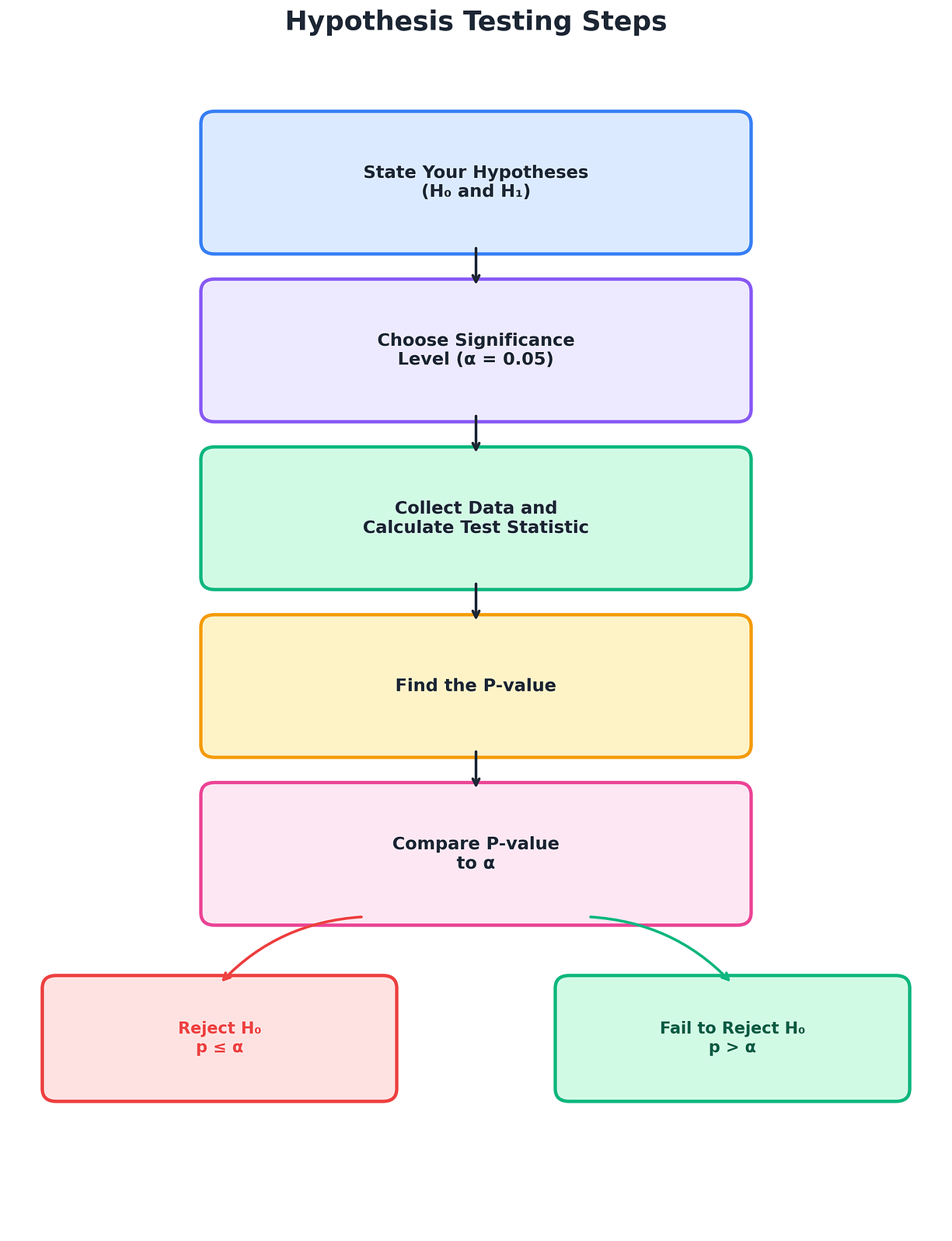
이것이 바로 가설 검정입니다.
가설 검정의 전체 구조가 여기에 담겨 있습니다.
먼저 기본 가정(귀무가설, H₀)을 세웁니다.
그 다음 증거(데이터)를 확인합니다.
증거가 충분히 강하면 기본 가정을 기각합니다.
그렇지 않으면 기존 가정을 유지합니다.
이제 조금 더 공식적으로 살펴보겠습니다.
H₀ (귀무가설, Null Hypothesis) 은 언제나 가장 평범한 주장입니다.
"새로운 일은 일어나지 않았다."
"차이는 존재하지 않는다."
"약은 효과가 없다."
"새로운 웹사이트 디자인은 아무런 변화를 만들지 못했다."
H₀는 현재 상태(status quo)입니다.
기본값(default)입니다.
"지나가세요. 여기에는 특별한 일이 없습니다."라는 주장입니다.
반면 H₁ (대립가설, Alternative Hypothesis) 은 우리가 실제로 관심을 가지는 주장입니다.
"이 약은 효과가 있다."
"새로운 디자인은 클릭 수를 증가시켰다."
"새로운 교육 방법은 성적을 향상시켰다."
H₁은 우리가 데이터가 지지해 주기를 바라는 주장입니다.
당신의 임무는 데이터를 수집한 뒤 단 하나의 질문을 던지는 것입니다.
"이 데이터는 H₀가 참이라고 가정했을 때 발생하기에는 너무 드문 결과인가?"
만약 그렇다면 H₀를 더 이상 믿지 않게 됩니다.
여기서 중요한 점이 있습니다.
우리는 H₁을 직접 증명하지 않습니다.
대신 H₀에 대한 반박 사례를 구축합니다.
그 반박이 충분히 강하면 H₀를 기각하고, 결과적으로 H₁이 선택됩니다.
반대로 반박이 충분하지 않다면 이렇게 말합니다.
"나는 H₀를 기각할 만큼 충분한 증거를 가지고 있지 않다."
이 표현을 주의 깊게 보세요.
우리는 "H₀가 참이다"라고 말하지 않습니다.
우리는 "H₀를 기각할 수 없다"라고 말합니다.
이 둘은 매우 다른 의미입니다.
배심원이 "무죄(Innocent)"라고 말하는 것이 아니라 "유죄가 아님(Not Guilty)"이라고 말하는 것과 같습니다.
알파(α). 당신이 받아들일 준비가 된 위험의 크기
데이터를 보기 전에 먼저 기준선을 정해야 합니다.
어느 정도의 증거가 있어야 "충분하다"고 판단할 것인가?
이 기준을 알파(α, 유의수준)라고 부릅니다.
가장 일반적으로 사용하는 값은 α = 0.05입니다.
즉, 5%입니다.
그런데 여기서 말하는 5%는 정확히 무엇을 의미할까요?
의미는 다음과 같습니다.
만약 실제로는 아무 일도 일어나지 않았고(H₀가 참이라면), 현재 관측된 것과 같은 수준으로 극단적인 데이터가 순전히 우연 때문에 나타날 확률이 5%밖에 되지 않는다는 뜻입니다.
다르게 말하면, 당신은 우주를 향해 이렇게 말하는 것입니다.
"내가 어떤 결과를 통계적으로 유의하다고 판단할 때, 그 판단이 틀릴 가능성을 5%까지는 받아들이겠다."
그렇다면 왜 하필 0.05일까요?
놀랍게도 자연법칙 때문은 아닙니다.
1920년대 통계학자 로널드 피셔(Ronald Fisher)가 제안했고, 이후 과학계 전체가 그 기준을 널리 채택했기 때문입니다.
즉, 0.05는 물리학의 법칙이 아니라 관례(convention)입니다.
예를 들어 입자물리학자들은 새로운 입자를 발견했다고 발표할 때 거짓 경보(False Alarm)를 거의 허용할 수 없습니다.
그래서 α = 0.0000003과 같은 매우 엄격한 기준을 사용합니다.
반면 일부 사회과학 연구에서는 탐색적 연구(exploratory research)를 수행할 때 α = 0.10을 사용하기도 합니다.
중요한 것은 특정 값이 아니라 원칙입니다.
알파는 반드시 데이터를 보기 전에 정해야 합니다.
데이터를 본 뒤에 알파를 정하는 것은 마치 다트를 먼저 던진 다음, 다트가 꽂힌 위치를 중심으로 과녁을 그리는 것과 같습니다.
P-값(P-value). 과학계에서 가장 많이 오해받는 숫자
2025년에 발표된 한 연구에 따르면, 심리학 논문 중 더 강력한 p-값(더 작은 p-값)을 보고한 논문일수록 더 좋은 학술지에 게재되고 더 많은 인용을 받는 경향이 있었습니다.
이로 인해 연구자들은 의식적이든 무의식적이든 작은 p-값을 얻기 위해 노력하게 되는 왜곡된 유인이 생겼습니다.
그래서 p-값이 실제로 무엇을 의미하는지 정확히 이해하는 것이 더욱 중요합니다.
이번에는 아주 엄밀하게 정의해 보겠습니다.
p-값은 귀무가설(H₀)이 참이라고 가정할 때, 현재 결과와 같거나 그보다 더 극단적인 결과가 관측될 확률입니다.
이 문장의 모든 단어에는 의미가 담겨 있습니다.
하나씩 살펴보겠습니다.
"귀무가설이 참이라고 가정할 때(IF the null hypothesis is true)"
p-값은 아무 일도 일어나지 않는 가상의 세계에서 계산됩니다.
즉, 다음과 같은 질문입니다.
"이 약이 실제로는 전혀 효과가 없고 우리가 단지 무작위 잡음(random noise)만 보고 있다면, 지금처럼 극적인 데이터가 얼마나 자주 나타날까?"
"현재 결과와 같거나 그보다 더 극단적인(at least as extreme)"
p-값은 지금 관측된 결과만 고려하는 것이 아닙니다.
그보다 더 놀라운 결과들까지 모두 포함합니다.
"확률(probability)"
p-값은 0과 1 사이의 숫자입니다.
0에 가까울수록 "이런 결과가 우연히 나타날 가능성은 거의 없다"는 의미입니다.
1에 가까울수록 "이 정도 결과는 우연히도 충분히 발생할 수 있다"는 의미입니다.
실제 예시
동전을 100번 던졌다고 가정해 봅시다.
그 결과 앞면이 60번 나왔습니다.
귀무가설은 다음과 같습니다.
"이 동전은 공정하다(앞면과 뒷면이 각각 50%)."
이때 p-값은 다음 질문에 대한 답입니다.
"만약 동전이 정말 공정하다면, 100번 던져서 앞면이 60번 이상 나올 확률은 얼마인가?"
계산해 보면 약 0.028입니다.
즉, 2.8% 정도입니다.
상당히 낮은 확률입니다.
따라서 우리는 보통 H₀를 기각하고 "이 동전은 편향되어 있을 가능성이 있다"고 결론 내립니다.
이번에는 앞면이 52번 나왔다고 가정해 봅시다.
이 경우 p-값은 약 0.69입니다.
공정한 동전으로 100번 던져서 52번 앞면이 나오는 일은 매우 흔하게 발생합니다.
따라서 동전을 의심할 이유가 없습니다.
의사결정 규칙
규칙은 매우 단순합니다.
p ≤ α (보통 0.05)
→ H₀를 기각한다.
→ 결과는 통계적으로 유의하다(statistically significant).
p > α
→ H₀를 기각하지 못한다.
→ 증거가 충분하지 않다.

분포 양쪽 꼬리 부분에 있는 작은 음영 영역이 바로 p-값입니다.
그 영역이 작아질수록 H₀의 입장은 점점 더 불리해집니다.
이제 정말 중요한 이야기를 해보겠습니다.
p-값이 무엇이 아닌지를 이해해야 합니다.
이 오해가 너무 흔해서 미국통계학회(American Statistical Association)는 2016년에 공식 성명을 발표하기도 했습니다.
p-값은 H₀가 참일 확률이 아니다
다음과 같은 말은 틀렸습니다.
"p = 0.03이니까 아무 일도 일어나지 않았을 확률은 3%다."
아닙니다.
p-값은 가설의 진실 여부를 말해주는 숫자가 아닙니다.
데이터가 얼마나 놀라운지를 말해주는 숫자입니다.
p-값은 결과가 우연히 발생했을 확률이 아니다
비슷해 보이지만 정확히는 다릅니다.
p-값은 "모든 것이 우연에 의해 발생했다고 가정할 때, 이 정도로 극단적인 데이터가 나타날 확률"입니다.
p-값은 효과의 크기나 중요성을 측정하지 않는다
예를 들어 어떤 약이 혈압을 0.1 mmHg 낮춘다고 가정해 봅시다.
의학적으로는 거의 쓸모없는 효과입니다.
하지만 5만 명을 대상으로 실험하면 p-값이 0.001처럼 매우 작게 나올 수도 있습니다.
즉, 통계적으로 유의하다(significant) 와 실질적으로 중요하다(important) 는 전혀 다른 개념입니다.
이 부분은 뒤에서 다시 살펴보겠습니다.
p = 0.04와 p = 0.06은 본질적으로 다른 결과가 아니다
많은 사람들이 0.05를 절벽처럼 취급합니다.
0.049는 "진짜 효과", 0.051은 "아무것도 아님"처럼 생각하는 것입니다.
하지만 실제로는 두 값 사이에 본질적인 차이는 거의 없습니다.
0.05를 경계로 세상을 흑백으로 나누는 관행은 현대 과학이 안고 있는 가장 큰 문제 중 하나로 지적되고 있습니다.
제1종 오류(Type I Error)와 제2종 오류(Type II Error): 틀리는 두 가지 방식
가설 검정 결과를 바탕으로 결정을 내릴 때, 당신은 정확히 두 가지 방식으로 틀릴 수 있습니다.
제1종 오류(Type I Error): 거짓 경보(False Alarm)
H₀를 기각했지만 실제로는 H₀가 참인 경우입니다.
즉, "무언가 일어나고 있다!" 라고 결론 내렸지만 사실은 아무 일도 일어나지 않은 상황입니다.
예를 들어, 스팸 필터가 어머니가 보낸 이메일을 스팸으로 분류한 경우입니다.
또는 누군가 토스트를 태웠을 뿐인데 화재 경보기가 울린 경우입니다.
제1종 오류가 발생할 확률은 바로 α(알파)입니다.
만약 α = 0.05라면, 실제로 아무 일도 일어나지 않았음에도 약 5%의 확률로 "중요한 일이 발생했다"고 잘못 판단하게 됩니다.
이것은 검정을 수행하기 위해 지불하는 비용입니다.
그리고 그 비용은 당신이 직접 선택한 것입니다.
제2종 오류(Type II Error): 신호를 놓침(Missed Signal)
이번에는 반대 상황입니다.
H₀를 기각하지 않았지만 실제로는 H₀가 틀린 경우입니다.
즉, 실제로 의미 있는 일이 일어나고 있었는데 그것을 발견하지 못한 상황입니다.
예를 들어, 스팸 필터가 피싱 메일을 정상 메일로 통과시킨 경우입니다.
또는 실제 화재가 발생했는데 "또 누가 토스트를 태웠겠지"라고 생각하고 경보를 무시한 경우입니다.
제2종 오류가 발생할 확률은 β(베타)라고 부릅니다.
그리고 1 − β를 검정력(Power)이라고 합니다.
(검정력은 뒤에서 더 자세히 다룹니다.)
이미지: 제1종 오류와 제2종 오류를 보여주는 2×2 결과표 (True Positive, False Positive, True Negative, False Negative)
가능한 결과는 총 네 가지입니다.
그중 두 가지는 올바른 판단이고, 나머지 두 가지는 오류입니다.
보통 색상으로 구분하여 어떤 결과가 맞고 어떤 결과가 틀렸는지 표시합니다.
어떤 오류가 더 심각할까?
정답은 상황에 따라 다릅니다.
의료 검사
의료 검진에서는 제2종 오류가 매우 위험할 수 있습니다.
실제 질병이 있는데 이를 놓치는 경우입니다.
암 환자를 정상이라고 판단하는 것은 생명을 위협할 수 있습니다.
따라서 이런 상황에서는 약간의 거짓 경보가 발생하더라도 실제 환자를 놓치지 않는 것이 더 중요합니다.
그래서 더 많은 양성 사례를 발견하기 위해 α를 조금 높게 설정(예: 0.10)하기도 합니다.
그 대가로 거짓 양성(False Positive)은 늘어나게 됩니다.
형사 재판
형사 재판에서는 일반적으로 제1종 오류가 더 심각하다고 여겨집니다.
무고한 사람을 유죄로 판결하는 경우입니다.
그래서 법체계는 일부 유죄인 사람이 풀려나는 한이 있더라도 무고한 사람을 감옥에 보내지 않는 방향으로 설계되어 있습니다.
이것이 바로 "합리적 의심의 여지가 없을 정도로(Beyond a Reasonable Doubt)"라는 매우 엄격한 기준이 사용되는 이유입니다.
통계적으로 표현하면 매우 낮은 α를 사용하는 것과 비슷합니다.
신약 승인
신약 승인 과정에서는 미국 FDA가 일반적으로 α = 0.05를 사용합니다.
왜냐하면 두 종류의 오류가 모두 심각하기 때문입니다.
효과 없는 약을 승인하면 (제1종 오류) 돈이 낭비되고 환자에게 잘못된 희망을 줄 수 있습니다.
반대로 효과 있는 약을 승인하지 않으면(제2종 오류) 환자들은 실제 치료 기회를 잃게 됩니다.
0.05는 이 두 위험 사이의 절충안입니다.
가장 중요한 통찰
표본 크기가 고정되어 있다면
제1종 오류와 제2종 오류를 동시에 최소화할 수는 없습니다.
α를 낮추면 (거짓 경보 감소) 자동으로 β가 증가합니다 (실제 신호를 더 많이 놓침)
반대로 실제 신호를 더 잘 잡으려 하면 거짓 경보도 늘어나게 됩니다.
두 오류를 동시에 줄일 수 있는 유일한 방법은 하나뿐입니다.
더 많은 데이터를 수집하는 것입니다.
Z-검정(Z-Test). 가장 먼저 배우지만 실제로는 가장 나중에 사용하는 검정
이제 실제 통계 검정으로 들어가 보겠습니다.
먼저 z-검정부터 시작하겠습니다. z-검정은 이후에 등장하는 거의 모든 검정의 기초가 되기 때문입니다.
z-검정은 모집단의 표준편차(σ)를 알고 있을 때, 표본평균과 모집단평균을 비교하는 검정입니다.
여기서 중요한 부분은 바로 "σ를 알고 있을 때"입니다.
그리고 이것이 현실에서 z-검정을 거의 사용하지 않는 이유이기도 합니다.
모집단의 표준편차를 안다는 것은 보통 엄청난 규모의 과거 데이터가 있거나, 산업 표준 규격이 이미 공개되어 있다는 뜻입니다.
마치 시험을 보는데 정답지를 함께 가지고 있는 것과 비슷합니다.
있으면 매우 유용하지만, 실제로는 거의 주어지지 않습니다.
그럼에도 불구하고 z-검정은 매우 중요합니다.
왜냐하면 z-검정의 논리가 이후 등장하는 모든 검정의 논리와 동일하기 때문입니다.
이것만 이해하면 나머지는 거의 같은 아이디어의 변형에 불과합니다.
공식
z = (x̄ - μ) / (σ / √n)
처음 보면 다소 위협적으로 보일 수 있습니다.
하지만 실제로는 그렇지 않습니다.
각 부분을 하나씩 해석해 보겠습니다.
분자의 의미 (x̄ − μ)
위쪽 부분인 (x̄ − μ)는 단순히 표본평균과 모집단평균의 차이입니다.
즉, "내 표본 평균이 모집단 평균에서 얼마나 떨어져 있는가?"를 측정합니다.
분모의 의미 (σ / √n)
아래쪽 부분인 (σ / √n)은 표준오차(Standard Error)라고 부릅니다.
표본평균이 순수한 우연 때문에 얼마나 흔들릴 수 있는지를 나타내는 값입니다.
쉽게 말하면 데이터의 잡음(noise) 수준입니다.
여기서 σ를 √n으로 나누는 이유도 직관적입니다.
표본이 커질수록 평균은 더 안정적으로 추정됩니다.
즉, 데이터가 많을수록 잡음은 줄어듭니다.
그래서 표준오차는 표본 크기의 제곱근에 반비례합니다.
z값의 의미
z값은 "표본평균이 모집단 평균으로부터 몇 개의 표준오차만큼 떨어져 있는가?" 를 나타냅니다.
예를 들어, z = 1 → 평균에서 표준오차 1개만큼 떨어져 있음
z = 2 → 평균에서 표준오차 2개만큼 떨어져 있음 → 이미 꽤 드문 결과
z = 3 → 평균에서 표준오차 3개만큼 떨어져 있음 → 이제는 무언가 의심해 봐야 하는 수준
왜 z = 2나 z = 3이 중요한가?
앞에서 배운 68–95–99.7 법칙을 기억해 보세요.
정규분포에서는
약 95%의 값이 평균으로부터 ±2 표준편차 안에 존재합니다.
즉, 평균에서 2 표준편차보다 멀리 떨어진 값은 우연히 발생할 확률이 5% 미만입니다.
평균에서 3 표준편차 이상 떨어진 값은 우연히 발생할 확률이 0.3% 미만입니다.
따라서 z값이 매우 크다면 단순한 우연이라고 보기 어려워집니다.

파란색 선은 z-분포(표준정규분포)입니다.
빨간색 점선은 표본 수가 3개밖에 되지 않는 경우의 t-분포입니다.
양쪽 꼬리가 훨씬 두꺼운 것을 볼 수 있습니다.
이 추가적인 폭은 표본이 매우 작을 때 발생하는 불확실성을 반영한 것입니다.
이제 전체 과정을 실제 파이썬 코드로 살펴보겠습니다.
# numpy handles the math, scipy.stats has the test functions
# These two libraries power 90% of statistics work in Python
import numpy as np
from scipy import stats
#…
# SCENARIO: A battery factory claims their batteries last
# 500 hours on average, with a known sigma of 30 hours.
# "Known" because they've been manufacturing for 20 years
# and have data on millions of batteries.
# We're the quality inspector. We grabbed 36 batteries off
# the line and tested them. Do they actually last 500 hours?
population_mean = 500 # what the factory claims (mu)
population_std = 30 # known from 20 years of data (sigma)
#…
# Our 36 test results in hours
# 36 is our sample size (n). It's > 30, so CLT is happy.
sample = [510, 485, 520, 505, 515, 498, 525, 490, 512,
508, 530, 495, 518, 503, 522, 487, 510, 505,
515, 502, 528, 493, 510, 507, 520, 499, 513,
506, 518, 497, 515, 504, 522, 509, 511, 503]
#…
# Step 1: Calculate the sample mean (x-bar)
# np.mean() adds everything up and divides by count
sample_mean = np.mean(sample)
n = len(sample) # should be 36
#…
# Step 2: Calculate the z-statistic
# Top: how far our sample mean is from the claimed mean
# Bottom: the standard error (sigma / sqrt of n)
# The standard error shrinks as n grows, which is why
# bigger samples give you more precise estimates
z_stat = (sample_mean - population_mean) / (population_std / np.sqrt(n))
#…
# Step 3: Get the p-value
# stats.norm.cdf(z) gives the area under the curve LEFT of z
# For a two-tailed test (we're checking "different from 500"
# in either direction), we need both tails
# abs() because the tail area is the same whether z is
# positive or negative (the curve is symmetric)
p_value = 2 * (1 - stats.norm.cdf(abs(z_stat)))
#…
# Step 4: Make the call
alpha = 0.05
print(f"Sample mean: {sample_mean:.2f} hours")
print(f"Z-statistic: {z_stat:.4f}")
print(f"P-value: {p_value:.4f}")
if p_value <= alpha:
print("REJECT H0 → batteries are NOT lasting 500 hours")
else:
print("FAIL TO REJECT H0 → no evidence against the claim")
Sample mean: 508.61 hours
Z-statistic: 1.7222
P-value: 0.0850
FAIL TO REJECT H0 → no evidence against the claim
각 단계가 실제로 무엇을 했는지 살펴봅시다.
1단계에서는 표본의 중심, 즉 표본평균을 계산했습니다.
2단계에서는 그 중심이 공장에서 주장한 값과 얼마나 떨어져 있는지 측정했습니다. 단순한 차이만 보는 것이 아니라 데이터의 잡음(noise) 수준까지 고려하여 조정했습니다.
3단계에서는 다음 질문을 던졌습니다.
"만약 공장의 주장이 사실이라면, 지금처럼 극단적인 표본이 관측될 확률은 얼마나 될까?"
4단계에서는 그 확률을 우리가 미리 정해둔 허용 오차인 α = 0.05와 비교했습니다.
그렇다면 왜 항상 z-검정을 사용하지 않을까?
이유는 간단합니다.
z-검정을 사용하려면 모집단의 표준편차 σ를 알고 있어야 하기 때문입니다.
하지만 현실에서는 거의 그런 일이 없습니다.
마지막으로 누군가가 당신에게 모집단 전체의 정확한 표준편차를 알려준 적이 언제였나요?
실제 분석에서는 대부분 모집단의 표준편차를 알 수 없습니다.
대신 표본 데이터를 이용해 σ를 추정합니다.
그리고 바로 그 순간,
z-검정이 아니라 t-검정을 사용해야 합니다.
T-검정(T-Test). 양조장에서 태어나 세상 어디에서나 사용되다
과학사에서 제가 가장 좋아하는 이야기 중 하나를 소개하겠습니다.
1908년, 윌리엄 실리 고셋(William Sealy Gosset)이라는 화학자가 아일랜드 더블린의 기네스(Guinness) 양조장에서 일하고 있었습니다.
그의 업무는 품질 관리였습니다.
그는 보리의 작은 생산 배치(batch)가 품질 기준을 충족하는지 검정해야 했지만, 사용할 수 있는 표본의 크기가 매우 작았습니다.
문제는 당시의 통계 기법들이 대부분 정규분포를 기반으로 하고 있었고, 큰 표본을 전제로 설계되었다는 점이었습니다.
작은 표본에서는 결과가 신뢰할 수 없었습니다.
그리고 당시에는 아무도 이 문제를 해결하지 못했습니다.
그래서 고셋은 직접 문제를 해결했습니다.
그가 바로 t-검정을 발명한 것입니다.
하지만 여기서 재미있는 문제가 있었습니다.
기네스는 직원들이 연구 결과를 공개적으로 발표하는 것을 엄격하게 금지하고 있었습니다.
경쟁사들이 회사의 과학적 품질 관리 기법을 배우는 것을 원하지 않았기 때문입니다.
그래서 고셋은 자신의 연구를 본명이 아닌 "Student"라는 필명으로 발표했습니다.
그의 정체는 1937년 사망한 뒤에야 공개되었습니다.
바로 이것이 Student's t-test(스튜던트 t-검정)이라는 이름의 유래입니다.
학생들을 위한 검정이라서 그런 이름이 붙은 것이 아닙니다.
한 양조장 화학자가 가장 중요한 연구를 가명으로 몰래 발표해야 했기 때문입니다.
t-검정은 z-검정과 무엇이 다를까?
차이는 단 하나입니다.
z-검정은 모집단의 표준편차 σ를 알고 있다고 가정합니다.
반면 t-검정은 모집단의 표준편차를 모르기 때문에 표본 표준편차 s를 사용하여 추정합니다.
이 과정에서 추가적인 불확실성이 생깁니다.
그리고 t-분포는 바로 그 불확실성을 반영합니다.
앞에서 본 것처럼 t-분포는 정규분포보다 꼬리(tail)가 더 두껍습니다.
꼬리가 두껍다는 것은 무엇을 의미할까요?
H₀를 기각하려면 더 강한 증거가 필요하다는 뜻입니다.
생각해 보면 매우 합리적입니다.
데이터의 퍼짐 정도를 정확히 모르고 추정만 하고 있으니, 결론을 내릴 때 더 신중해야 하기 때문입니다.
즉, 불확실성이 크다 → 더 강한 증거가 필요하다 → t-분포의 꼬리가 더 두꺼워진다라는 관계가 성립합니다.
표본이 커지면 어떻게 될까?
표본 크기가 커질수록 표본 표준편차 s는 모집단 표준편차 σ에 점점 가까워집니다.
그 결과 t-분포도 점점 정규분포와 비슷해집니다.
일반적으로 n ≈ 30정도가 되면 두 분포는 거의 구분하기 어려울 정도로 비슷해집니다.
t-검정의 세 가지 종류
t-검정은 크게 세 가지 종류가 있습니다.
각각 서로 다른 질문에 답하기 위해 사용됩니다.
이제 하나의 시나리오를 이용해 세 가지 t-검정을 모두 살펴보겠습니다.
그렇게 하면 이들이 서로 어떻게 연결되는지 자연스럽게 이해할 수 있습니다.
단일 표본 t-검정(One-Sample T-Test)
"이 집단은 기준값과 다른가?"
상황을 가정해 봅시다.
당신은 학교 관리자입니다.
전국 평균 시험 점수는 75점입니다.
당신은 자신의 학교 학생들이 전국 평균과 다른 성과를 보이는지 알고 싶습니다.
그래서 학생 25명의 시험 점수를 무작위로 추출했습니다.
from scipy import stats
import numpy as np
#…
# 25 exam scores from our school
# These are real-ish numbers, not cherry-picked
scores = [82, 78, 85, 90, 73, 88, 76, 81, 84, 79,
87, 91, 77, 83, 86, 80, 74, 89, 82, 85,
78, 84, 88, 76, 81]
#…
# H0: our school's average = 75 (same as national)
# H1: our school's average ≠ 75 (different)
# This is two-tailed because we're not specifying which
# direction the difference goes
#…
# ttest_1samp takes two arguments:
# 1) your data (the 25 scores)
# 2) popmean: the value you're comparing against (75)
# It returns two things: the t-statistic and the p-value
# scipy does ALL the math internally (calculates the sample
# mean, sample std, standard error, degrees of freedom)
t_stat, p_value = stats.ttest_1samp(scores, popmean=75)
#…
print(f"Sample mean: {np.mean(scores):.2f}")
print(f"Sample std: {np.std(scores, ddof=1):.2f}")
print(f"T-statistic: {t_stat:.4f}")
print(f"P-value: {p_value:.4f}")
print(f"df: {len(scores) - 1}")
#…
# ddof=1 in np.std() means "sample standard deviation"
# ddof stands for "delta degrees of freedom"
# We use ddof=1 because we're estimating from a sample,
# not calculating for an entire population
#…
alpha = 0.05
if p_value <= alpha:
print("→ REJECT H0: our school differs from national avg")
else:
print("→ FAIL TO REJECT: no significant difference found")
Sample mean: 82.28
Sample std: 5.09
T-statistic: 7.1556
P-value: 0.0000
df: 24
→ REJECT H0: our school differs from national avg
언제 사용하는가?
하나의 집단에 대한 데이터가 있고, 그것을 특정 기준값 하나와 비교하고 싶을 때 사용합니다.
독립 2표본 t-검정(Independent Two-Sample T-Test)
"이 두 집단은 서로 다른가?"
같은 학교를 예로 들어보겠습니다. 이번에는 질문이 조금 달라졌습니다.
당신은 두 가지 교수법을 비교하고 싶습니다.
A반은 전통적인 강의식 수업을 받았습니다.
B반은 학생 참여형 수업을 받았습니다.
두 반의 학생들은 서로 다른 사람들입니다.
이제 당신은 다음 질문에 답하고 싶습니다.
"어느 교수법이 더 높은 시험 점수를 만들어냈는가?"
from scipy import stats
import numpy as np
#…
# Class A: 20 students, traditional lectures
class_a = [72, 78, 81, 85, 74, 79, 83, 77, 80, 76,
82, 75, 79, 84, 73, 81, 78, 80, 76, 83]
#…
# Class B: 20 students, interactive method
class_b = [85, 88, 82, 90, 87, 84, 91, 86, 89, 83,
88, 85, 87, 92, 84, 86, 90, 88, 85, 87]
#…
# H0: mean(A) = mean(B) (no difference between methods)
# H1: mean(A) ≠ mean(B) (one method is better)
#…
# ttest_ind = independent samples t-test
# "Independent" because the students in class A are
# completely different people from the students in class B
# There's no overlap, no pairing, no connection
t_stat, p_value = stats.ttest_ind(class_a, class_b)
#…
print(f"Class A mean: {np.mean(class_a):.2f}")
print(f"Class B mean: {np.mean(class_b):.2f}")
print(f"Difference: {np.mean(class_b) - np.mean(class_a):.2f}")
print(f"T-statistic: {t_stat:.4f}")
print(f"P-value: {p_value:.6f}")
#…
alpha = 0.05
if p_value <= alpha:
print("→ REJECT H0: the methods produce different results")
else:
print("→ FAIL TO REJECT: no significant difference found")
Class A mean: 78.80
Class B mean: 86.85
Difference: 8.05
T-statistic: -7.8486
P-value: 0.000000
→ REJECT H0: the methods produce different results
언제 사용하는가?
서로 다른 사람이나 객체로 구성된 두 개의 독립적인 집단을 비교하고 싶을 때 사용합니다.
대응표본 t-검정(Paired T-Test)
"같은 집단에서 변화가 있었는가?"
같은 학교를 예로 들어 보겠습니다. 이번에는 또 다른 질문입니다.
당신은 학생 15명을 선택했습니다.
새로운 학습 앱을 사용하기 전에 시험을 치르게 합니다.
그리고 4주 동안 앱을 사용한 후 다시 시험을 치르게 합니다.
두 번 모두 같은 학생들입니다.
당신이 알고 싶은 것은 다음과 같습니다.
"이 학습 앱이 실제로 도움이 되었는가?"
이 경우는 독립 2표본 t-검정과 다릅니다.
왜냐하면 서로 다른 두 집단을 비교하는 것이 아니라, 같은 사람들을 두 번 측정하고 있기 때문입니다.
각 학생의 "사용 전" 점수에는 대응되는 "사용 후" 점수가 존재합니다.
즉, 모든 "이전(Before)" 점수는 짝이 되는 "이후(After)" 점수를 가지고 있습니다.
from scipy import stats
import numpy as np
#…
# SAME 15 students, measured TWICE
# This pairing is why it's called a "paired" test
before = [65, 70, 72, 68, 74, 66, 71, 69, 73, 67,
70, 72, 68, 75, 71]
after = [75, 78, 80, 74, 82, 73, 79, 77, 81, 74,
78, 80, 76, 83, 79]
#…
# H0: the app made no difference (mean difference = 0)
# H1: the app made a difference (mean difference ≠ 0)
#…
# ttest_rel = related (paired) samples t-test
# "Related" because each before has a matching after
# Under the hood, it calculates the difference for each
# pair and then does a one-sample t-test on those
# differences, testing if the mean difference = 0
t_stat, p_value = stats.ttest_rel(before, after)
#…
# Let's also look at the individual improvements
diffs = np.array(after) - np.array(before)
print(f"Before mean: {np.mean(before):.2f}")
print(f"After mean: {np.mean(after):.2f}")
print(f"Mean improvement: {np.mean(diffs):.2f} points")
print(f"T-statistic: {t_stat:.4f}")
print(f"P-value: {p_value:.6f}")
#…
alpha = 0.05
if p_value <= alpha:
print("→ REJECT H0: the app made a significant difference")
else:
print("→ FAIL TO REJECT: improvement was not significant")
Before mean: 70.07
After mean: 77.93
Mean improvement: 7.87 points
T-statistic: -36.5401
P-value: 0.000000
→ REJECT H0: the app made a significant difference
왜 여기서 그냥 독립 2표본 t-검정을 사용하지 않을까요?
그 이유는 대응표본 t-검정이 대응 관계를 활용할 수 있을 때 더 높은 검정력을 가지기 때문입니다.
예를 들어 학생 3번이 원래 시험을 잘 보지 못하는 학생이라고 가정해 봅시다.
그 학생의 약점은 앱 사용 전 점수에도 나타나고, 앱 사용 후 점수에도 나타납니다.
대응표본 t-검정은 각 학생의 점수 자체가 아니라, 각 짝(pair) 안에서의 차이를 분석합니다.
즉, 사용 후 점수 − 사용 전 점수에 집중합니다.
이렇게 하면 학생마다 가지고 있는 고유한 기본 능력 차이가 자연스럽게 제거됩니다.
반면 독립 2표본 t-검정은 이러한 대응 관계를 완전히 무시합니다.
사용 전 점수와 사용 후 점수를 마치 서로 아무 관련 없는 사람들의 점수처럼 취급합니다.
결국 이미 가지고 있는 유용한 정보를 버리게 되는 셈입니다.
만약 데이터에 자연스러운 대응 관계가 존재한다면, 같은 사람을 두 번 측정한 경우, 같은 기계를 서로 다른 시점에 측정한 경우, 같은 도시를 정책 시행 전후로 측정한 경우처럼 관측값들이 서로 짝을 이룬다면, 항상 대응표본 t-검정을 사용하는 것이 좋습니다.
언제 어떤 검정을 사용해야 할까? 이것만 기억하면 되는 의사결정 트리

같은 내용을 빠르게 참고할 수 있도록 표로 정리하면 다음과 같습니다.
+---------------------------+-------------------------------+
| Situation | Use This Test |
+---------------------------+-------------------------------+
| Know σ, large sample | Z-test |
| Don't know σ, one group | One-sample t-test |
| Don't know σ, two groups | Independent two-sample t-test |
| Same subjects, two times | Paired t-test |
+---------------------------+-------------------------------+
솔직히 말하면, 어떤 검정을 사용해야 할지 확신이 서지 않는다면 그냥 t-검정을 사용해도 됩니다.
만약 모집단 표준편차 σ를 알고 있다면(아마 대부분은 아닐 것입니다), z-검정을 사용하면 됩니다.
그리고 표본 크기 n이 30 이상이라면 어느 검정을 사용하든 결과는 거의 동일하게 나옵니다.
왜냐하면 t-분포는 표본 크기가 커질수록 점점 정규분포에 수렴하기 때문입니다.
비유하자면, t-검정은 만능 도구가 들어 있는 스위스 아미 나이프(Swiss Army Knife)와 같습니다.
반면 z-검정은 통계학 교과서 속 연습문제에 가깝습니다.
단측검정(One-Tailed) vs 양측검정(Two-Tailed)
짧지만 중요한 이야기
대립가설(H₁)을 설정할 때는 방향성에 대한 선택을 하게 됩니다.
양측검정(Two-Tailed)
"평균이 X와 다른가?"라는 질문입니다.
평균이 더 클 수도 있고 더 작을 수도 있습니다.
어느 방향인지는 중요하지 않습니다.
단지 차이가 존재하는지만 알고 싶습니다.
이 경우 귀무가설을 기각하는 영역(정규분포 그래프에서 음영 처리된 영역)은 분포의 양쪽 끝에 나뉘어 배치됩니다.
따라서 전체 유의수준 α는 양쪽 꼬리에 절반씩 나누어집니다.
각 꼬리는 α/2를 갖게 됩니다.
단측검정(One-Tailed)
"평균이 X보다 큰가?" 또는 "평균이 X보다 작은가?"
와 같이 특정 방향을 가지고 있는 경우입니다.
이때는 유의수준 α 전체가 한쪽 꼬리에만 배치됩니다.
따라서 그 방향의 효과를 탐지하기가 더 쉬워집니다.

왼쪽은 기각 영역 전체를 한쪽 꼬리에 집중시킨 단측검정입니다.
오른쪽은 기각 영역을 양쪽 꼬리에 나누어 배치한 양측검정입니다.
전체 면적(α)은 같지만 민감도는 크게 달라집니다.
실무에서의 원칙
특별한 이유가 없다면 양측검정을 기본값으로 사용하세요.
단측검정은 특정 방향의 효과를 찾는 능력(검정력)을 높여주지만, 반대 방향의 효과는 완전히 놓치게 됩니다.
예를 들어 어떤 약물이 혈압을 올릴 수도 있고 내릴 수도 있다면, 우리는 두 가능성을 모두 고려해야 합니다.
따라서 양측검정이 적절합니다.
반면 약물의 작동 원리상 혈압을 높이는 것이 물리적으로 불가능하다면, 그때는 단측검정을 사용하는 것이 정당화될 수 있습니다.
신뢰구간(Confidence Interval)
답을 범위로 표현하는 방법
가설 검정은 보통 "예" 또는 "아니오"라는 결론을 제공합니다.
반면 신뢰구간은 하나의 숫자가 아니라 범위(range)를 제공합니다.
둘 다 동일한 수학적 원리에서 출발하지만, 실제로는 신뢰구간이 더 많은 정보를 제공하는 경우가 많습니다.
95% 신뢰구간이란?
95% 신뢰구간은 다음과 같은 방식으로 만들어진 구간입니다.
만약 동일한 실험을 100번 반복한다면,
생성된 신뢰구간 중 약 95개는 실제 모집단 모수(true population parameter)를 포함하게 됩니다.
반드시 이해해야 할 중요한 차이점
95% 신뢰구간은 다음을 의미하지 않습니다.
"실제 값이 이 구간 안에 있을 확률이 95%다."
이 표현은 틀렸습니다.
실제 모집단의 값은 고정되어 있습니다.
그 값은 구간 안에 있거나, 아니면 구간 밖에 있습니다.
확률적으로 움직이는 것은 실제 값이 아니라 신뢰구간을 만드는 절차(method)입니다.
즉, 95%라는 숫자는 특정 신뢰구간 하나에 대한 확률이 아니라,
신뢰구간을 생성하는 방법의 장기적인 성공률을 의미합니다.
다르게 말하면, 동일한 방식으로 무수히 많은 신뢰구간을 만들었을 때,
그중 약 95%가 실제 값을 포함하도록 설계된 방법이라는 뜻입니다.

import numpy as np
from scipy import stats
#…
# Same school exam scores
scores = [82, 78, 85, 90, 73, 88, 76, 81, 84, 79,
87, 91, 77, 83, 86, 80, 74, 89, 82, 85,
78, 84, 88, 76, 81]
#…
sample_mean = np.mean(scores)
n = len(scores)
#…
# Standard error = sample std / sqrt(n)
# ddof=1 because we're working with a sample, not population
# sem() is a shortcut that does exactly this calculation
se = stats.sem(scores)
#…
# stats.t.interval builds the confidence interval
# Arguments:
# confidence level (0.95 for 95%)
# df: degrees of freedom (n - 1)
# loc: center of interval (our sample mean)
# scale: standard error (how much the mean bounces around)
ci = stats.t.interval(0.95, df=n-1, loc=sample_mean, scale=se)
#…
print(f"Sample mean: {sample_mean:.2f}")
print(f"95% CI: ({ci[0]:.2f}, {ci[1]:.2f})")
# This means we're 95% confident the true population
# mean falls somewhere in this range
Sample mean: 82.28
95% CI: (80.18, 84.38)
가설 검정과의 관계
만약 95% 신뢰구간(CI)에 귀무가설의 값이 포함되어 있지 않다면, 유의수준 α = 0.05인 양측검정에서는 H₀를 기각하게 됩니다.
두 방법은 동일한 수학을 서로 다른 방식으로 표현한 것에 불과합니다.
신뢰구간은 단순히 "유의한가 아닌가"만 알려주는 것이 아니라, 실제 값이 존재할 수 있는 그럴듯한 범위까지 보여주기 때문에 더 많은 정보를 제공합니다.
자유도(Degrees of Freedom). 15초면 충분합니다.
데이터가 10개 있다고 가정해 봅시다. 그리고 그 데이터의 평균을 이미 알고 있습니다. 그러면 10개 값 중 9개만 자유롭게 정할 수 있습니다. 마지막 10번째 값은 전체 평균이 맞아떨어지도록 자동으로 결정되어야 합니다. 이렇게 자유롭게 변할 수 있는 9개의 값이 바로 자유도입니다.
단일 표본 t-검정에서는 df = n − 1입니다. 독립 2표본 t-검정에서는 df ≈ n₁ + n₂ − 2입니다. 대응표본 t-검정에서는 df = n_pairs − 1입니다.
자유도가 낮을수록 t-분포의 꼬리는 더 두꺼워집니다. 즉, 통계적으로 유의한 결과를 얻기 위해 더 강한 증거가 필요합니다. 반대로 자유도가 높아질수록 t-분포는 점점 z-분포(정규분포)와 비슷해집니다.
이것이 자유도의 전부입니다.
통계적 검정력(Statistical Power)과 효과 크기(Effect Size): 똑똑한 연구도 실패하는 이유
2015년, 대규모 연구 프로젝트가 이미 발표된 심리학 연구 100편을 재현하려고 시도했습니다.
그 결과, 단지 36%만이 두 번째 실험에서도 통계적으로 유의한 결과를 얻었습니다.
이것이 바로 재현성 위기(Replication Crisis)입니다.
그리고 그 주요 원인 중 하나는 많은 원래 연구들이 검정력이 부족(underpowered)했기 때문입니다.
즉, 연구자들이 찾고자 했던 효과를 신뢰성 있게 발견하기에 데이터가 충분하지 않았던 것입니다.
통계적 검정력(statistical power)은 실제로 효과가 존재할 때 검정이 H₀를 올바르게 기각할 확률을 의미합니다.
Power = 1 − β 입니다.
검정력이 0.80(가장 널리 사용되는 기준)이라면 실제 효과가 존재할 때 그것을 발견할 확률이 80%라는 뜻입니다.
검정력이 0.50이라면 실제 효과가 존재하더라도 발견할지 말지를 동전 던지기로 결정하는 것과 크게 다르지 않습니다.

초록색 영역이 검정력(power)입니다.
표본이 커지거나, 효과가 커지거나, α를 높이면 이 영역이 넓어집니다.
검정력을 높이는 방법은 네 가지가 있습니다.
더 많은 데이터: 표본 크기 n이 커질수록 추정이 더 정밀해지고 검정력도 높아집니다.
더 큰 효과: 실제 차이가 클수록 작은 차이보다 발견하기 쉽습니다.
더 높은 α: 유의수준을 0.05 대신 0.10으로 높이면 더 많은 효과를 발견할 수 있습니다. 하지만 그 대가로 거짓 경보도 늘어납니다.
더 적은 잡음: 데이터의 표준편차가 작을수록 신호가 더 선명하게 보입니다.
이제 효과 크기(Effect Size)에 대해 이야기해 봅시다.
효과 크기는 어떤 차이가 "통계적으로 유의한가"와 별개로, 그 차이가 얼마나 큰가를 측정합니다.
여기서부터 통계가 실제 의사결정과 연결되기 시작합니다.
평균을 비교할 때 가장 널리 사용하는 효과 크기 지표는 Cohen's d입니다.
d = (mean₁ - mean₂) / pooled_standard_deviation
코헨(Cohen)이 제안한 대략적인 기준은 다음과 같습니다.
- d = 0.2 → 작은 효과 (거의 눈에 띄지 않음)
- d = 0.5 → 중간 효과 (눈에 띔)
- d = 0.8 → 큰 효과 (무시하기 어려움)
왜 이것이 중요할까요?
예를 들어 참가자가 5만 명인 연구를 수행했다고 가정해 봅시다.
두 집단의 IQ 차이는 겨우 0.3점입니다.
그런데 표본이 너무 크다 보니 p-값은 0.001이 나왔습니다.
통계적으로 유의한가? 그렇습니다.
실질적으로 중요한가? 전혀 아닙니다.
효과 크기는 바로 이런 상황을 잡아냅니다.
p-값이 놓치는 부분을 효과 크기가 보완하는 것입니다.
반대로 최상위 학술지에 실린 연구가 p < 0.001을 보고했지만 d = 0.04라면 어떨까요?
그 연구는 분명 "실제 효과"를 발견한 것일 수 있습니다.
하지만 그 효과가 너무 작아서 현실에서는 누구도 체감할 수 없을 가능성이 높습니다.
반면 p = 0.07이라서 통계적으로 유의하지 않다고 판정된 연구라도 d = 0.9라면 어떨까요?
그 연구는 실제로 매우 중요한 효과를 발견했을 수 있습니다.
단지 표본 수가 부족해서 유의성 기준을 넘지 못했을 뿐입니다.
그래서 항상 두 가지를 함께 보고해야 합니다.
p-값만 보고 효과 크기를 보고하지 않는 것은 "무언가 변했습니다"라고 말하면서 "얼마나 변했는지"는 말하지 않는 것과 같습니다.
의사가 "환자 상태가 달라졌습니다" 라고만 말한다면, 당신은 당연히 이렇게 물을 것입니다.
"좋아진 건가요? 나빠진 건가요? 그리고 얼마나 달라졌나요?"
통계도 마찬가지입니다.
당신을 망하게 만들 실수들: 민망한 상황을 피하게 해드리겠습니다
저는 이 실수들을 정말 많이 봤습니다.
심지어 충분히 알고 있어야 할 사람들도 이런 실수를 합니다.
그중 일부는 저 자신이 저질렀던 실수이기도 합니다.
"H₀를 받아들였다"고 말하기
절대로 H₀를 받아들인다고 말하지 마세요.
우리는 단지 H₀를 기각하지 못했을 뿐입니다.
이 차이는 단순한 말장난이 아닙니다.
"우리는 H₀에 반대되는 증거를 찾지 못했다"와 "우리는 H₀가 참이라는 것을 증명했다"는 전혀 다른 이야기입니다.
증거가 없다는 것이 곧 부재의 증거는 아닙니다.
단지 표본이 너무 작았을 수도 있습니다.
P-해킹(P-Hacking)
같은 데이터에 대해 검정을 반복해서 수행합니다.
변수를 바꿔봅니다.
이상치를 제거해 봅니다.
단측검정과 양측검정을 바꿔봅니다.
그리고 마침내 p < 0.05가 나올 때까지 계속 시도합니다.
이것이 p-해킹입니다.
유의수준 α = 0.05에서 서로 독립인 가설을 20개 검정하면 평균적으로 1개 정도는 순전히 운 때문에 "통계적으로 유의한" 결과가 나옵니다.
2025년의 한 연구에 따르면, 현재는 부정행위가 포함된 과학 논문의 증가 속도가 정상적인 논문의 증가 속도보다 더 빠른 수준에 도달했다고 합니다.
P-해킹은 이러한 문제의 중요한 원인 중 하나입니다.
데이터에 맞지 않는 검정 사용하기
대응 관계가 있는 데이터를 독립 표본 검정으로 분석하면 유용한 정보를 버리게 됩니다.
모집단 표준편차 σ를 모르는 상황에서 z-검정을 사용하면 실제보다 지나치게 자신감 있는 결과를 얻게 됩니다.
표본 수가 매우 적은데 정규성 가정을 확인하지 않으면 결과 자체가 무의미해질 수도 있습니다.
효과 크기 무시하기
이미 설명했지만 너무 흔한 실수라서 한 번 더 언급할 가치가 있습니다.
통계적으로 유의하다(significant) 와 중요하다(important) 는 같은 의미가 아닙니다.
결과를 본 후에 α를 정하기
결과를 확인했더니 p-값이 0.048이 나왔습니다.
그 후에 "그럼 α를 0.05로 하자"라고 결정한다면, 그것은 과학이 아닙니다.
다트를 던진 후에 과녁을 그리는 것과 같습니다.
통계적 유의성과 현실적 중요성을 혼동하기
통계적으로 유의한 결과란 "순수한 우연만으로 발생했을 가능성이 낮다"는 의미입니다.
그것이
- 충분히 큰 효과라는 뜻도 아니고,
- 임상적으로 중요한 효과라는 뜻도 아니고,
- 사업 전략을 바꿀 만큼 가치 있는 결과라는 뜻도 아닙니다.
따라서 결과를 해석할 때는 항상 다음 질문을 던져야 합니다.
"유의한 것은 알겠는데, 그래서 뭐가 달라지는가?"
통계 분석에서 가장 중요한 질문 중 하나입니다.
이제 무엇을 해야 할까?
통계에 대해 읽는 것과 실제로 통계를 하는 것은 서로 다른 기술입니다.
하지만 그 둘 사이의 간격은 생각보다 크지 않습니다.
주피터 노트북을 열어보세요.
캐글(Kaggle)에서 데이터셋 하나를 찾아보세요. ("beginner friendly dataset"으로 검색하면 됩니다.)
그리고 질문 하나를 정해 보세요.
"이 지역의 평균 집값은 도시 전체 평균 집값과 다른가?"
그다음 적절한 검정을 선택하세요.
직접 실행해 보세요.
실수해 보세요.
고쳐 보세요.
실제로 통계를 잘하게 된 사람들은 모두 이런 방식으로 배웠습니다.
이 글 전체에서 단 세 가지만 기억해야 한다면 다음을 기억하세요.
첫째, p-값은 당신의 가설이 얼마나 참인지 알려주는 것이 아니라, 현재 데이터가 얼마나 놀라운지를 알려주는 값입니다.
둘째, 누군가 모집단 표준편차 σ를 직접 알려주지 않는 한 t-검정을 사용하세요. 그런데 그런 일은 거의 없습니다.
셋째, 통계적으로 유의하다(significant)와 중요하다(important)는 같은 의미가 아닙니다.
'통계의 기초' 카테고리의 다른 글
| 왜 로그가 주식 수익률에 사용되는가? (0) | 2026.05.31 |
|---|---|
| e와 로그 — 직관적으로 이해하기 (0) | 2026.05.30 |
| 두 데이터 계열: 기술통계와 추론통계가 세상을 움직이는 방식 (0) | 2026.05.26 |
| 통계에서 정규성을 검증하는 세 가지 방법 (0) | 2026.05.26 |
| 경영 의사 결정을 위한 가설 검정 - Part 2 (0) | 2026.05.17 |




댓글